Korelasi
Multigroup Structural Equation Modeling: Bagian 2️⃣
2026-06-25
Variance-covariance & correlation matrix 1️⃣
- Untuk melakukan SEM, maka perangkat lunak membutuhkan variance-covariance matrix untuk mengestimasi parameter model
- Pada bagian diagonal variance-covariance matrix menunjukkan varians, sedangkan sisanya adalah covariance
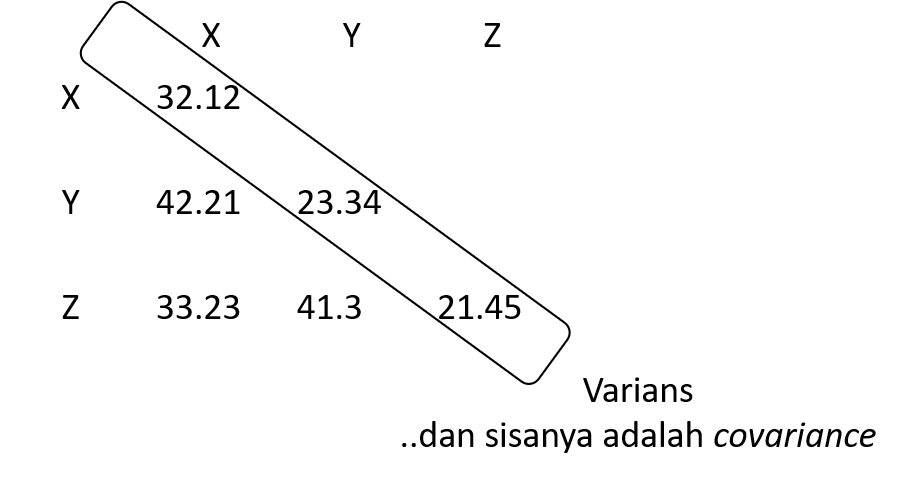
- Jumlah nilai unik (non-redundant information) dalam variance-covariance matrix adalah p(p+1)/2
- dimana p adalah jumlah observed variable
- Sehingga dengan contoh di atas maka jumlah nilai unik adalah 3(3+1)/2=6, yaitu 3 varians (diagonal) dan 3 covariance (sisanya)
Koreksi Atenuasi
Asumsi dasar dalam Psikometri adalah skor kasar (observed score) mengandung skor murni (true score) dan measurement error, sehingga dalam mengestimasi korelasi, measurement error perlu “dikontrol secara statistik” agar estimasi korelasi lebih akurat.
Dengan teknik koreksi atenuasi, kita dapat ‘mengontrol’ measurement error, sehingga kita dapat mengestimasi korelasi antar-variabel menggunakan true score-nya.
Tetapi apabila reliabilitas skala kita kurang baik, maka setelah dikoreksi koefisien korelasi bisa lebih dari 1 ❗
Misalnya diketahui bahwa korelasi observed scores antar dua variabel (rab) adalah 0.9 dan reliabilitas skala a (Cronbach’s α) adalah 0.6 dan skala b adalah 0.7, maka:

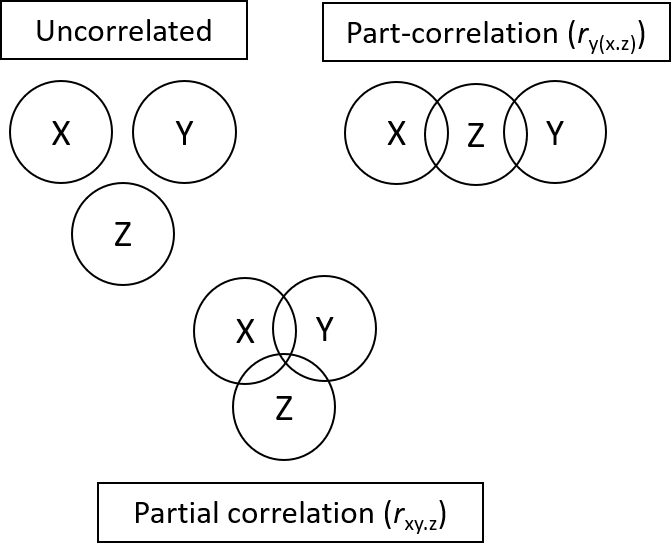
Korelasi Bivariat: Part dan partial correlation
Ada pertanyaan❓

Note
- Paparan disusun dengan menggunakan dan Quarto dengan template dari UNAIR Theme.
- Kontak saya via amelia.zein@psikologi.unair.ac.id