Dasar-Dasar Structural Equation Modeling (SEM)
Multigroup Structural Equation Modeling: Bagian 5️⃣
2026-06-25
Langkah-langkah melakukan analisis SEM
Spesifikasi model
Identifikasi model
Estimasi model
Menguji model
Memodifikasi model

Over-identified model
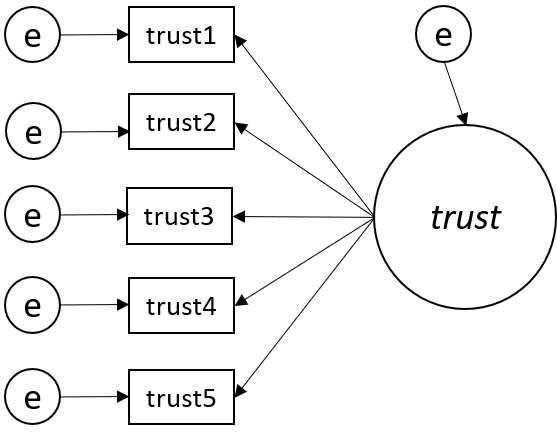
Pada model ini jumlah nilai unik (non-redundant information) dalam variance-covariance matrix = 5(5+1)/2 = 15
Sedangkan jumlah parameter jalur yang akan diestimasi adalah 11 (5 factor loading, 6 error variance), sehingga
df = 15-11 = 4 🥇
Model dapat diidentifikasi karena memenuhi syarat (over-identified)
Under-identified model
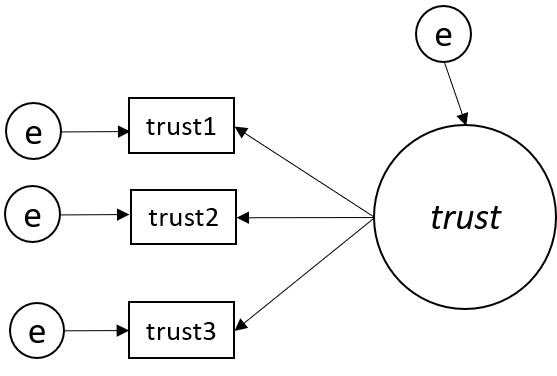
Pada model ini jumlah nilai unik (non-redundant information) dalam variance-covariance matrix = 3(3+1)/2 = 6
Sedangkan jumlah parameter jalur yang akan diestimasi adalah 7 (3 factor loading, 4 error variance), sehingga
df = 6-7 = -1 😢
Model tidak dapat diidentifikasi karena tidak memenuhi syarat (under-identified)
Just-identified model
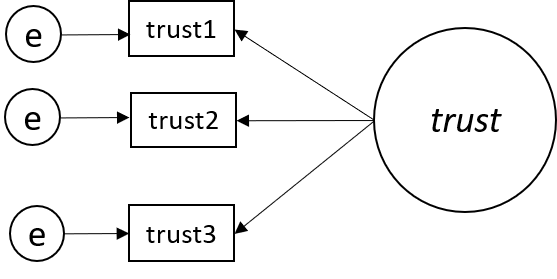
Pada model ini jumlah nilai unik (non-redundant information) dalam variance-covariance matrix = 3(3+1)/2 = 6
Sedangkan jumlah parameter jalur yang akan diestimasi adalah 6 (3 factor loading, 3 error variance), sehingga
df = 6-6 = 0 😢
Model tidak dapat diidentifikasi karena tidak ada ruang tersisa untuk melakukan estimasi (just-identified/saturated model)
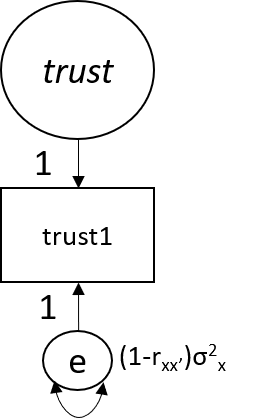
Variabel laten dengan 1 indikator
Masih bisa diestimasi dengan asumsi
- Item diasumsikan memiliki reliabilitas sempurna, sehingga varians error diconstraint = 0
- Reliabilitas diukur dengan test-retest, kemudian varians error diconstraint dengan mempertimbangkan reliabilitas dan standar deviasi
Menguji ketepatan model: Chi-square (χ²)
Dihitung dengan cara membandingkan model yang dihipotesiskan (implied model) dengan saturated model (model dengan fit sempurna, df = 0, yang mana semua parameter dibebaskan tanpa constraint)
- Incremental index seperti CFI dan NFI-lah yang membandingkan implied model dengan baseline/null model (model tanpa jalur sama sekali)
Umumnya, model dengan jumlah sampel yang besar akan memberikan hasil uji χ² yang signifikan, tetapi uji χ² yang signifikan ini tidak boleh diabaikan begitu saja❗
Selain χ², kita bisa mengevaluasi model dengan melihat alternative fit indices: Incremental index, Parsimony index, dan Absolute (standalone) index.

Mengestimasi jumlah sampel (semTools )
Peringatan
Pendekatan findRMSEAsamplesize dengan semTools di atas menguji kecocokan model secara global, yaitu apakah model kita secara keseluruhan cukup baik merepresentasikan data, dengan membandingkan dua nilai RMSEA (misalnya, 0.05 vs 0.08), tanpa memperhatikan parameter spesifik dalam model.
Demonstrasi power analysis dengan PAMLj
A priori power analysis dengan mempertimbangkan parameter spesifik dalam model dapat dilakukan dengan module PAMLj, yang asalnya menggunakan semPower di . Unduh demonstrasinya di sini.
Mari kita renungkan 🧘

Mari kita renungkan 🧘

Ada pertanyaan❓

Note
- Paparan disusun dengan menggunakan dan Quarto dengan template dari UNAIR Theme.
- Kontak saya via amelia.zein@psikologi.unair.ac.id