Linear Mixed-Effect (lme)
Menggunakan jamovi (Module GAMLj)
2026-06-25
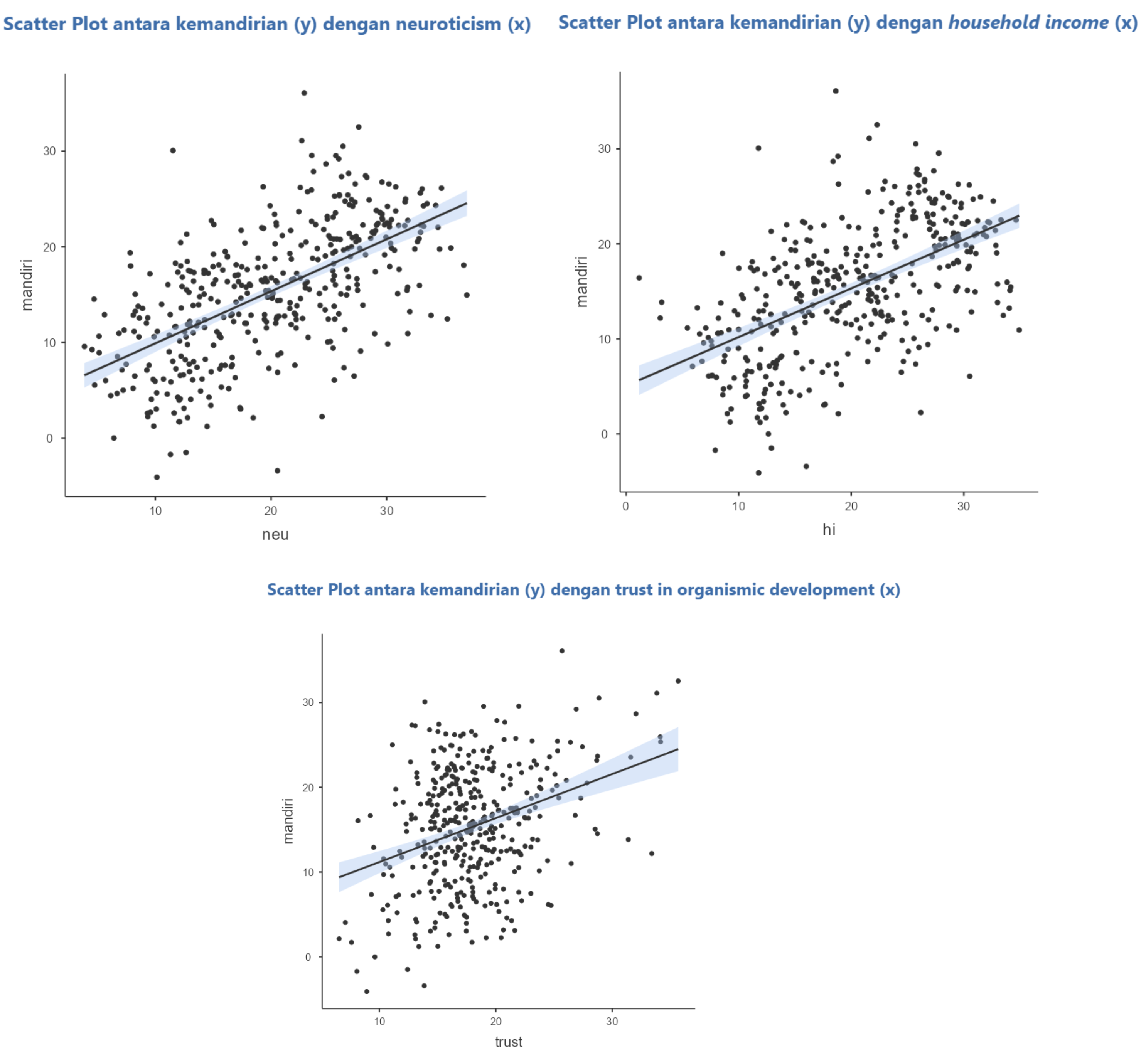
Scatterplot
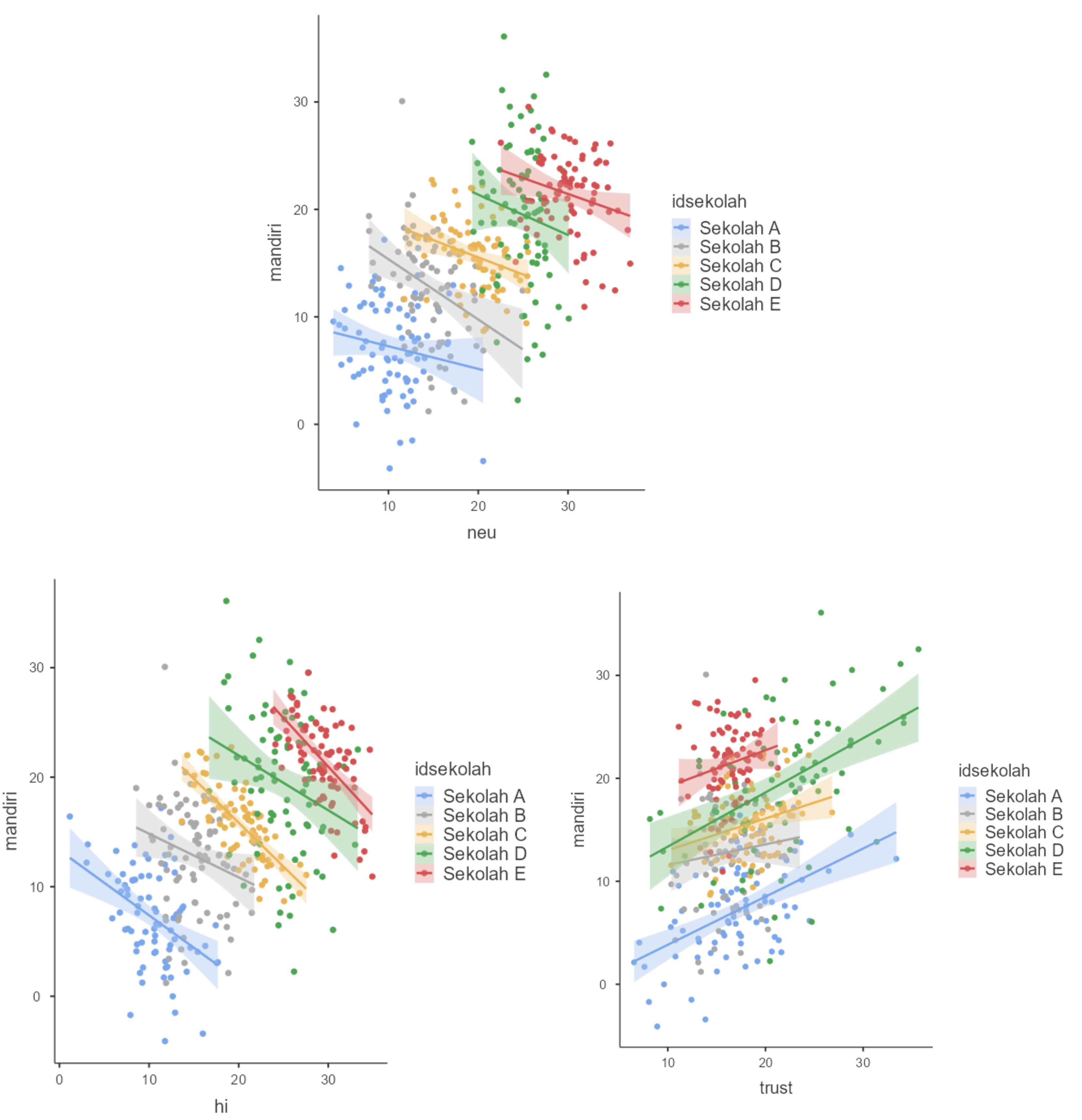
Scatterplot subkelompok
Ada yang janggal.. 🤔
Neuroticism dan pendapatan keluarga ternyata menunjukkan korelasi negatif dengan tingkat kemandirian, dengan intercept dan kemiringan (slopes) yang bervariasi di setiap sekolah.
Selain itu, meskipun trust menunjukkan korelasi positif di semua sekolah, tetapi intercept dan slope nya juga bervariasi di setiap sekolah
Padahal, berdasarkan analisis yang kita lakukan di sesi sebelumnya, disimpulkan bahwa neuroticism ibu dan kemandirian anak korelasinya positif (lihat output di samping).
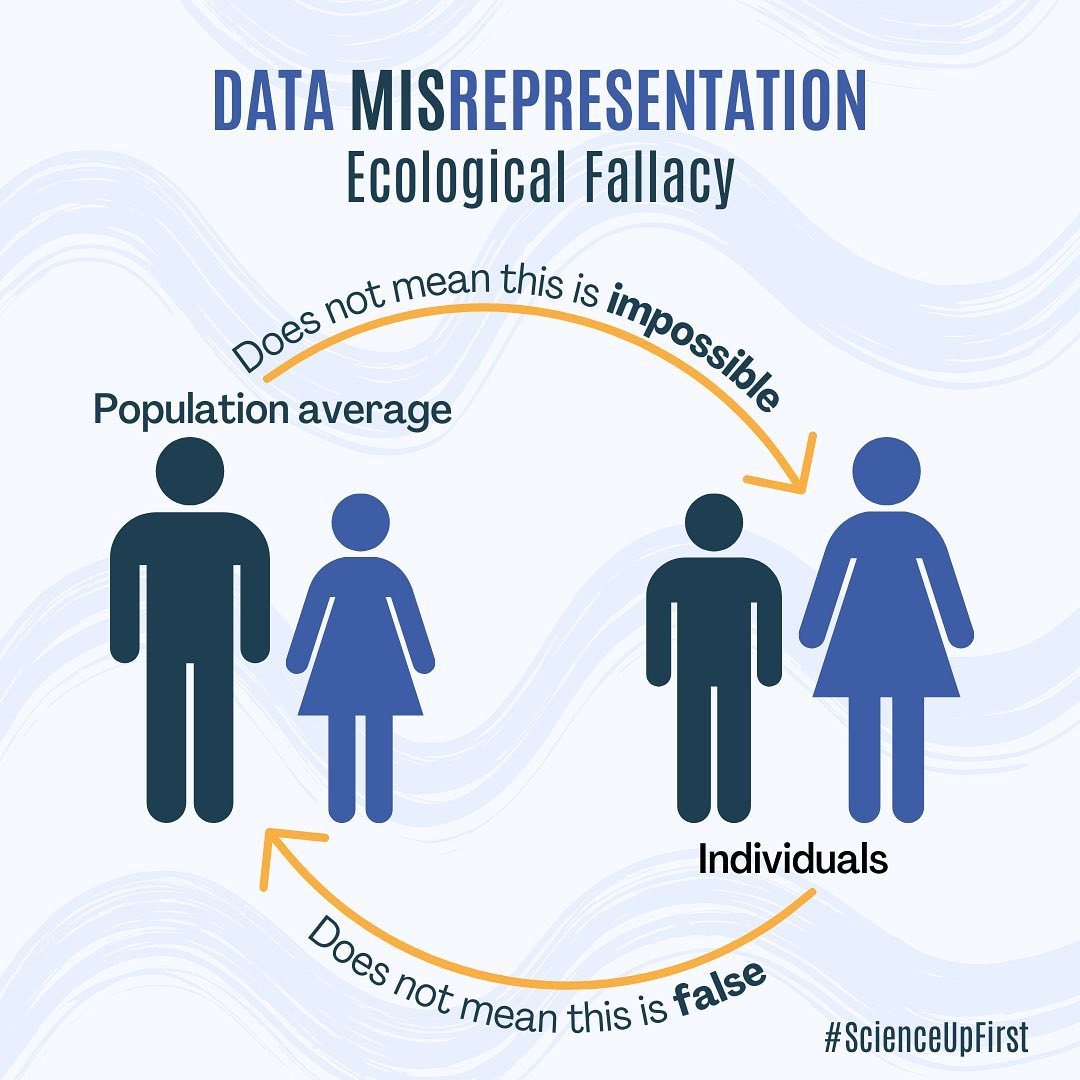
Simpson’s paradox
- Fenomena ini dikenal sebagai Simpson’s paradox
- ..yaitu ketika tren yang tampak di setiap sub-kelompok berbalik arah atau menghilang sama sekali ketika data dari semua kelompok digabungkan (aggregated).
- Kalau Simpson’s paradox diabaikan, kesimpulan bisa terkontaminasi ecological/atomistic fallacy
- Terjadi ketika peneliti salah menyimpulkan suatu gejala yang skalanya individual, padahal yang dianalisis sesungguhnya fenomena di level yang lebih besar (kelompok atau sub-kelompok) – atau sebaliknya
Struktur sampel bersarang/berjenjang
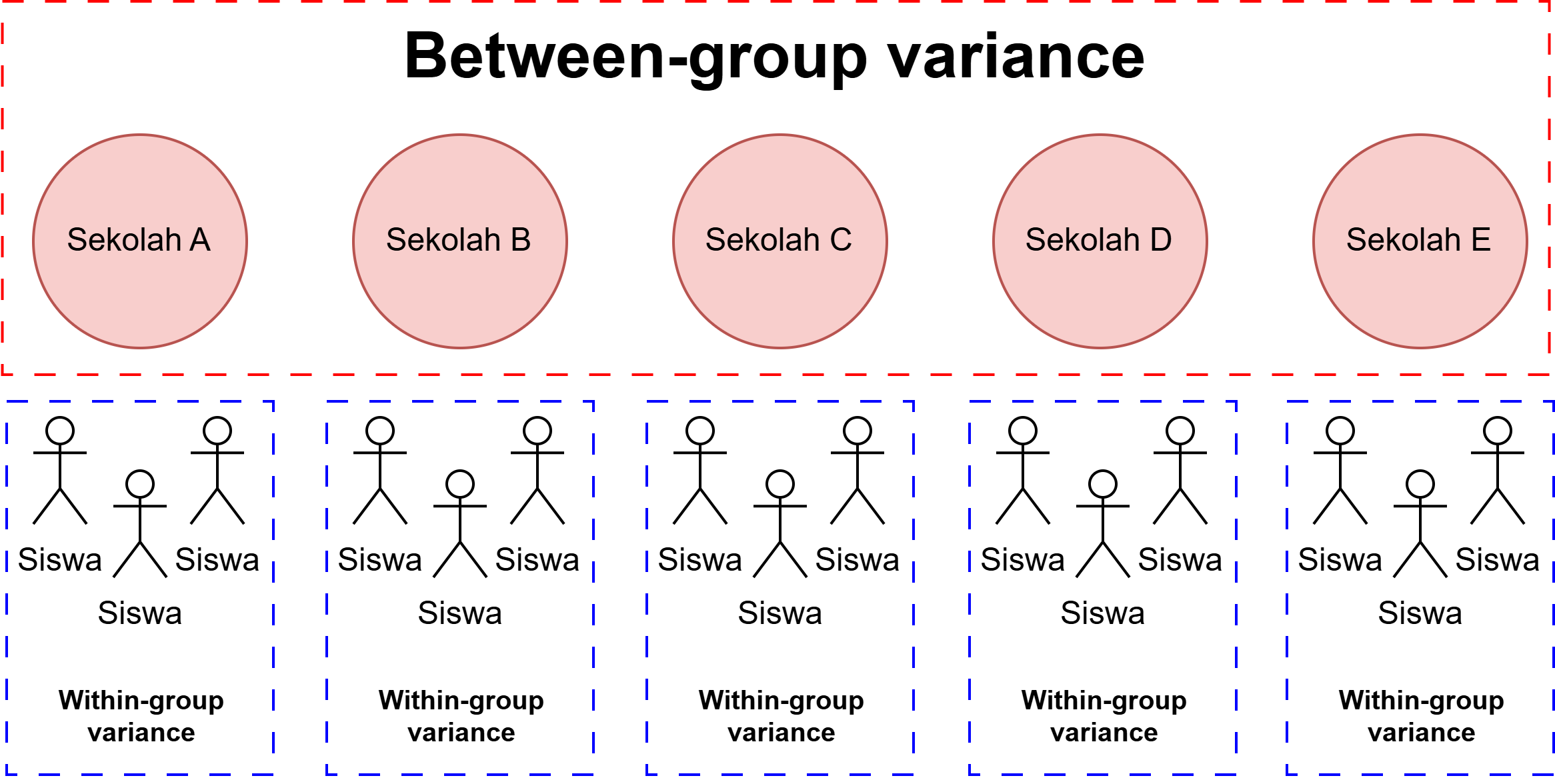
Fixed dan random effects
Model fixed effects
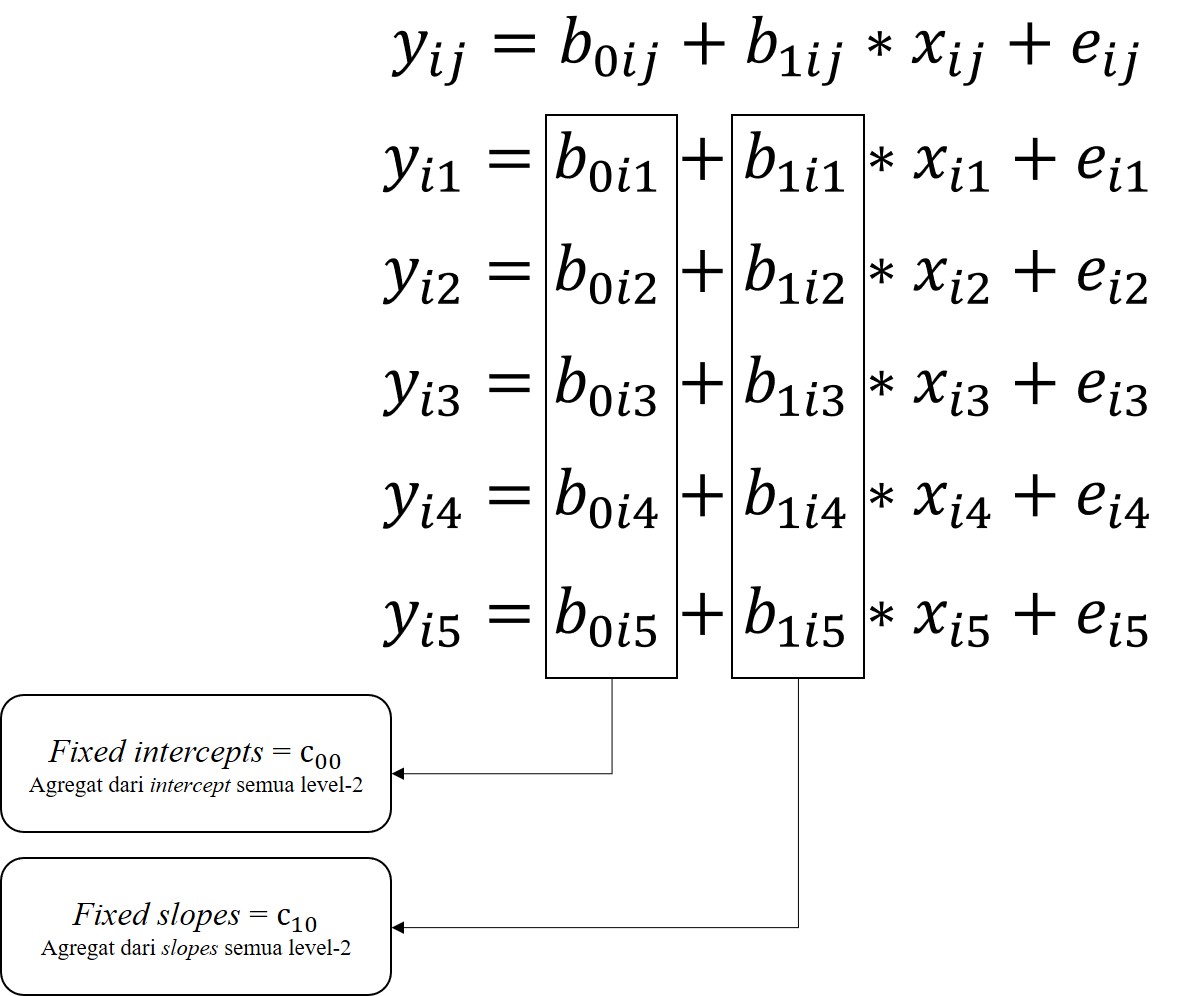
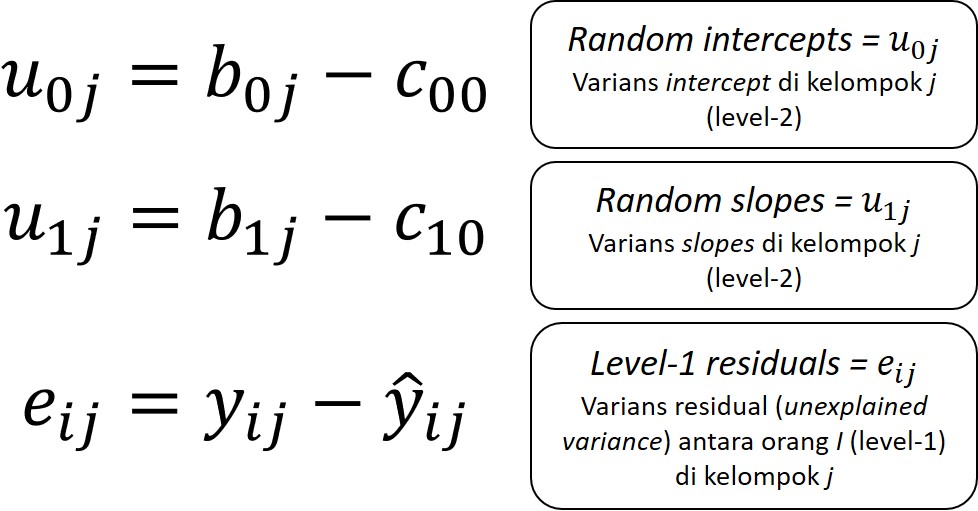
Model random effects
Full model
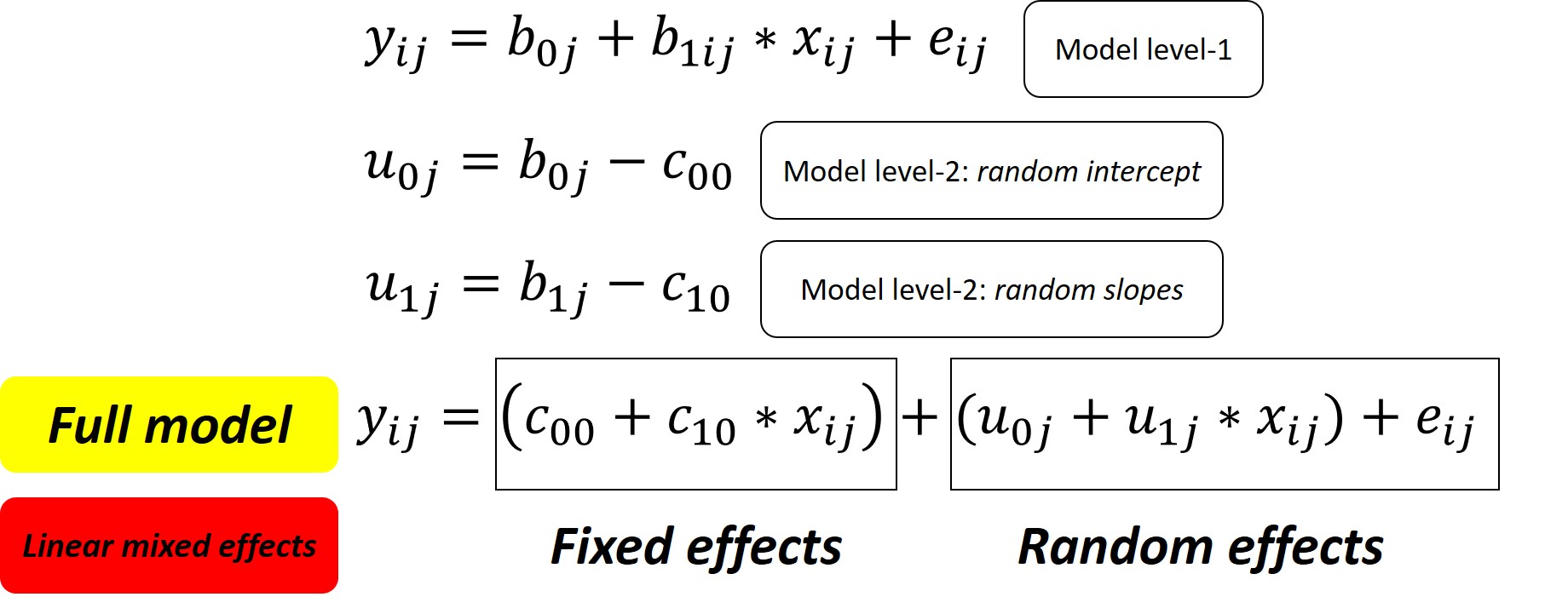
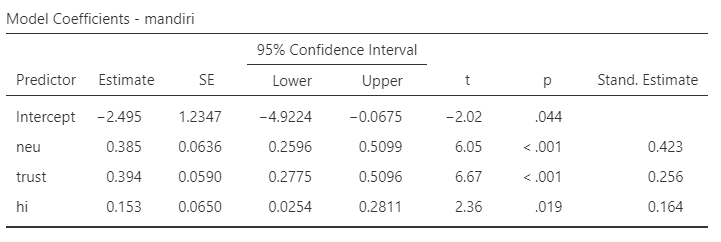
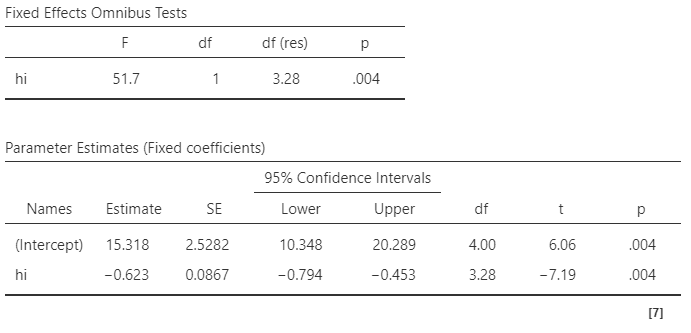
Fixed coefficients
- Tes kecocokan model (Omnibus Test) signifikan menggambarkan data (F(1, 3.28) = 51.7, p = .004)
- Korelasi antara tingkat pendapatan keluarga dengan kemandirian anak negatif, bukan positif, seperti hasil OLS sebelumnya
- Anak yang dibesarkan di keluarga dengan tingkat pendapatan yang tinggi, justru memiliki tingkat kemandirian yang rendah (B = -0.623 95% CI [-0.794, -0.453], SE = 0.086, t = -7.29, p = .004).
Random coefficients 1️⃣
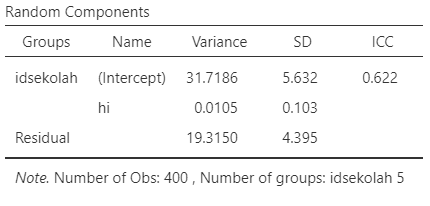
- Bandingkan varians random intercept (σ2U0) dan varians random slopes (σ2U1) dengan varians residual
- Varians random intercept lebih besar, sedangkan varians random slopes lebih kecil
- Artinya, tingkat kemandirian berbeda signifikan antar-sekolah, namun kekuatan korelasi/hubungan antara pendapatan rumah tangga dengan tingkat kemandirian relatif tidak berbeda antar sekolah
Random coefficients 2️⃣
- Menguji efek sekolah (kelompok)
Intra-class correlation, yaitu merupakan proporsi total varians variabel dependen yang dapat dijelaskan oleh variasi antar kelompok
Likelihood ratio test (LRT), yaitu teknik untuk menguji ada/tidaknya perbedaan varians antar-kelompok
LRT dan ICC juga bisa berfungsi sebagai indikator perlu/tidaknya
lmedilakukan

Random coefficients 3️⃣
ICC = 0.622, artinya 62.2% varians tingkat kemandirian siswa dijelaskan oleh perbedaan sekolah.
ICC di atas 0.1 biasanya menunjukkan
lmeadalah opsi yang lebih baik daripada OLS.LRT menunjukkan bahwa tidak ada perbedaan yang signifikan antara varians tingkat kemandirian antar-sekolah (LRT(2) = 0.627, p = .731), tetapi…
…struktur multilevel tetap dipertahankan mengingat besarnya ICC yang mengindikasikan ketidakindependenan observasi dalam sekolah yang sama.
LRT bisa jadi tidak signifikan karena power rendah akibat kita hanya punya sedikit kelompok (≤ 5 sekolah) dalam dataset
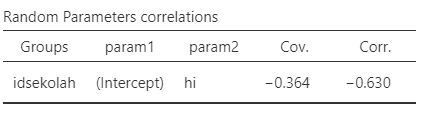
Random coefficients 4️⃣
Korelasi antara random slope dan random intercept (σU0U1) nilainya negatif, sedangkan fixed slopenya sendiri juga negatif
Artinya, sekolah yang siswanya rata-rata lebih mandiri, korelasi negatif pendapatan keluarga terhadap kemandirian lebih kuat (pendapatan tinggi, kemandirian justru makin turun drastis)
Jadi pendapatan keluarga lebih kuat dan negatif efeknya pada tingkat kemandirian siswa, di sekolah dengan rata-rata kemandirian yang tinggi (i.e., intercept tinggi)
Apakah artinya lingkungan sekolah tidak berdampak pada kemandirian anak?
- Belum tentu😉 Periksa dulu contextual effect
- Akan kita eksplorasi di bagian selanjutnya
Random coefficients 5️⃣
- Tabel di samping adalah intercept dan slopes untuk masing-masing sekolah
- Sekolah E adalah sekolah dengan rata-rata kemandirian yang paling tinggi (intercept paling besar)
- Sekaligus sekolah dengan hubungan negatif yang paling kuat/besar antara pendapatan keluarga dan kemandirian (slope paling negatif), konsisten dengan σU0U1 yang negatif

Model Comparison 1️⃣
AIC
- Apabila kita membandingkan “model kosong” (atas) dengan model yang ada prediktor (bawah), maka model yang terakhir lebih mampu menjelaskan varians kemandirian anak.
LRT test signifikan pada null model (atas) tetapi menjadi nonsignifikan pada model dengan prediktor (bawah)
Artinya, mempertahankan struktur bersarang memang pilihan tepat dan menguatkan dugaan sebelumnya bahwa LRT test yang tidak signifikan karena under-powered

Model Comparison 2️⃣
R2 (Nakagawa & Schielzeth, 2012)
Marginal: proporsi varians variabel dependen yang dapat dijelaskan oleh fixed models saja
Conditional: proporsi varians variabel dependen yang dapat dijelaskan oleh fixed dan random models sekaligus
Varians yang dapat dijelaskan oleh fixed model saja hanya 6.4%, sedangkan oleh keseluruhan model adalah 64.6%.

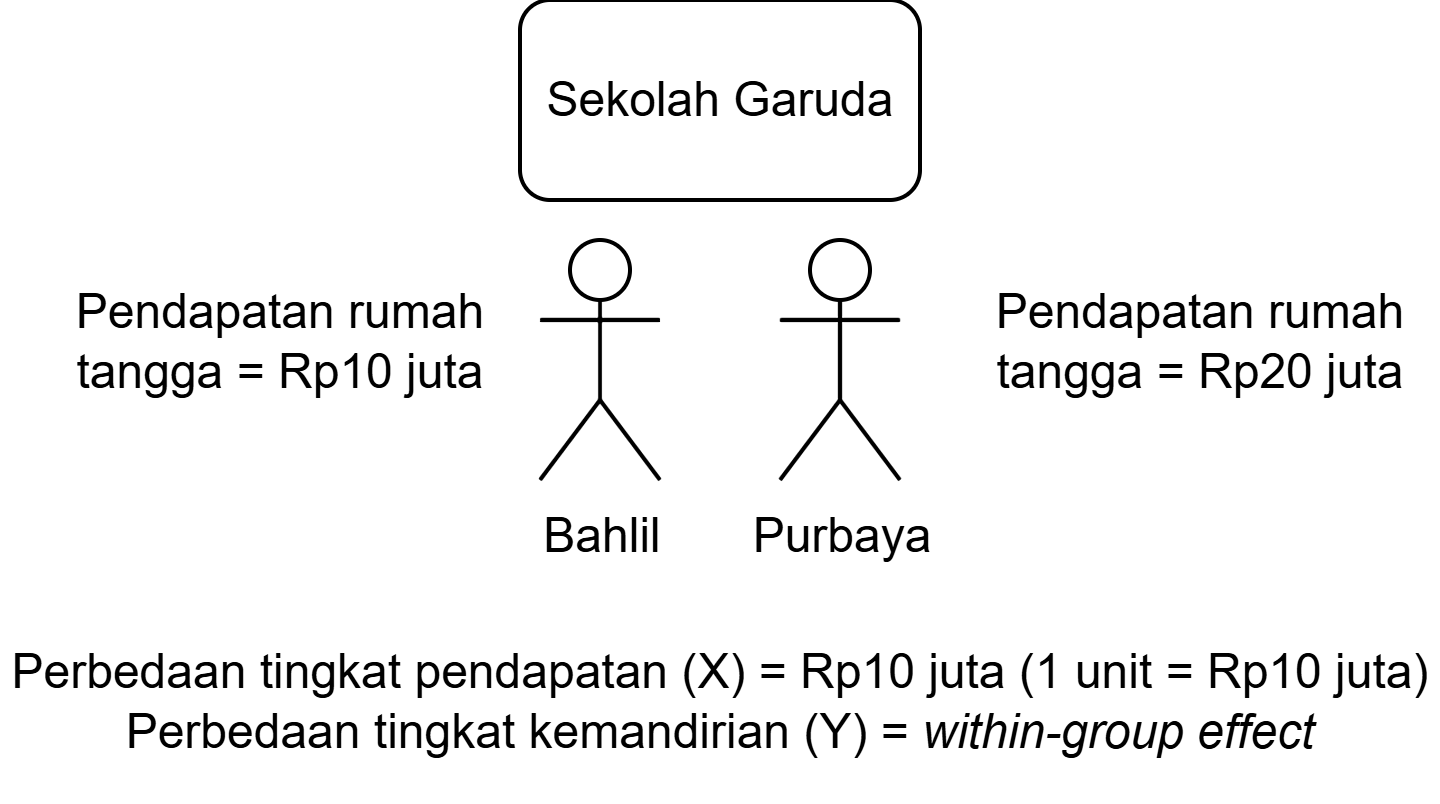
Within-group effect
- Seberapa besar selisih Y dari 2 orang yang berada di kelompok yang sama, ketika selisih X-nya sebesar 1 poin?
- Seberapa besar perbedaan tingkat kemandirian dua orang anak yang berada dalam sekolah yang sama, ketika selisih tingkat pendapatan keluarga mereka berbeda sebesar 1 poin?
- Didapatkan dengan cara melakukan group-mean centering (akan dijelaskan di bagian berikutnya)
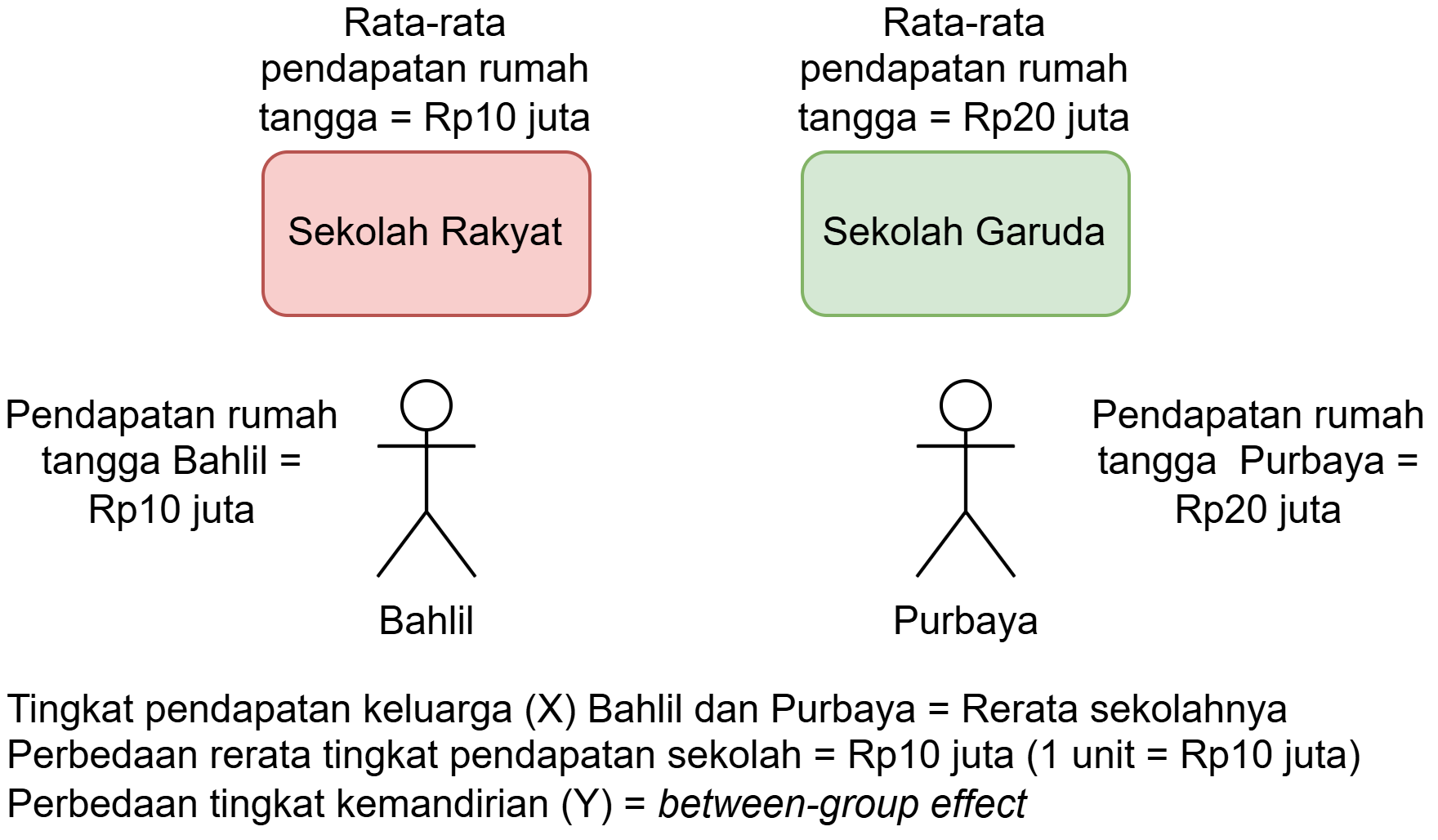
Between-group effect
- Seberapa besar selisih Y dari dua orang yang masing-masing berada pada rerata X kelompok mereka (yaitu, X individual = rerata kelompok), ketika rerata X kelompok mereka berbeda sebesar 1 poin?
- Seberapa besar perbedaan tingkat kemandirian dari dua siswa yang masing-masing berada pada rerata tingkat pendapatan keluarga di sekolah mereka (yaitu, tingkat pendapatan keluarga siswa tsb = rerata sekolah), ketika rerata tingkat pendapatan keluarga di sekolah mereka berbeda sebesar 1 poin?
- Didapatkan dengan cara memasukkan rerata kelompok ke dalam model
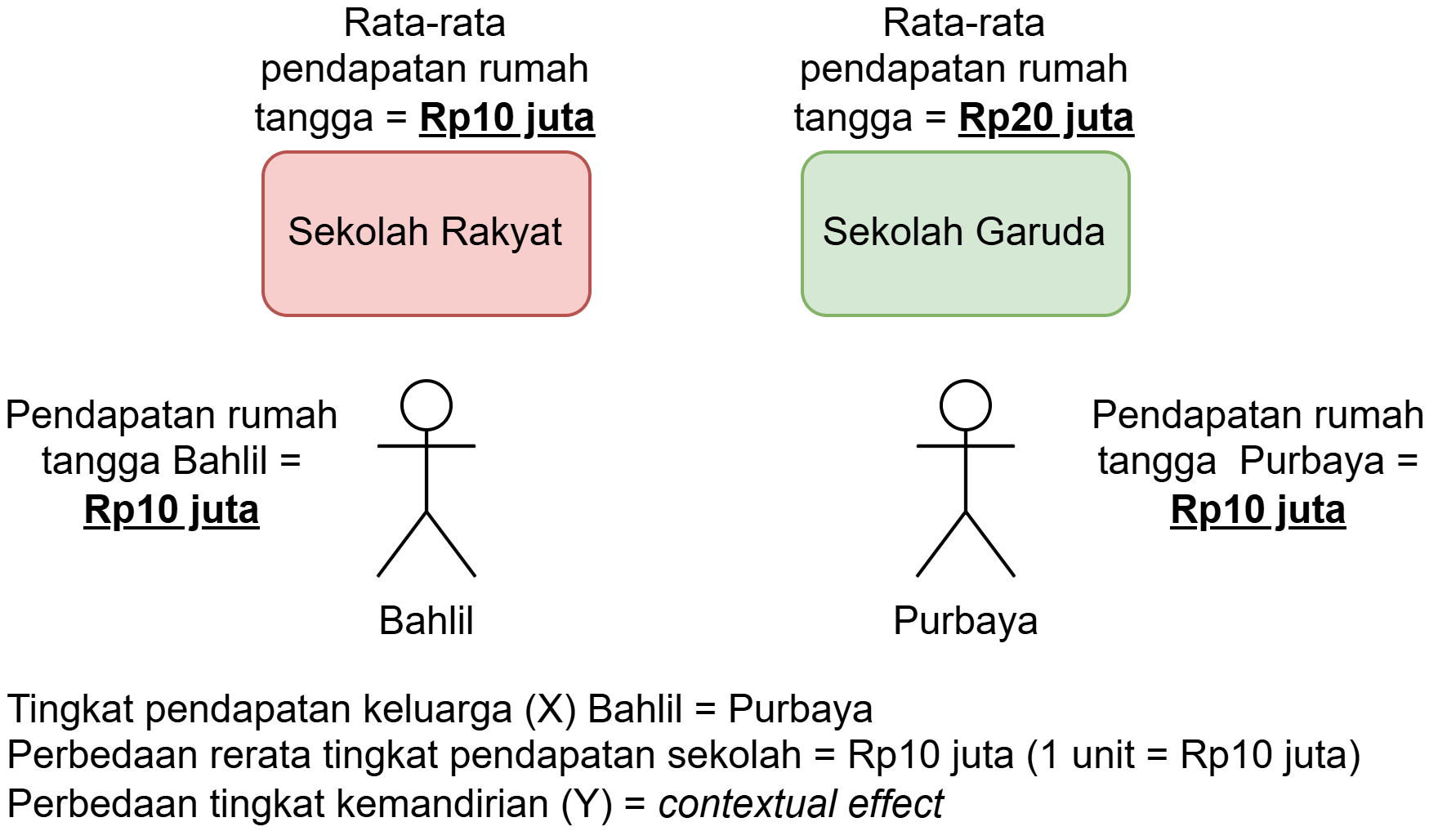
Contextual effects
- Seberapa besar selisih Y dua orang dari kelompok yang berbeda, namun dengan X yang sama, ketika rerata X kelompoknya berbeda sebesar 1 poin.
- Seberapa besar perbedaan tingkat kemandirian dua siswa dari dua sekolah yang berbeda, ketika tingkat pendapatan keluarga kedua siswa tersebut sama, tetapi rerata tingkat pendapatan keluarga di sekolah mereka berbeda sebesar 1 poin?
- Contoh contextual effects di psikologi: big-fish-little-pond effect (BFLPE)
Latihan 4️⃣: Contextual effects
Lakukan
lmedengan memasukkan hi_group_centered dan hi_gm dalam satu model yang samaMasukkan kedua variabel tersebut dalam fixed coefficients
Masukkan intercept (Intercept|idsekolah) dan hi_group_centered ke kotak random coefficients, kemudian pada menu effect correlation pilih
not correlatedPada menu covariates scaling, set keduanya pada
none(karena variabel sudah di group-mean centered secara manual)Lihat fixed slopes-nya untuk kedua prediktor
Warning
Jangan masukkan hi_gm ke random coefficient karena ini adalah rerata kelompok, sehingga nilainya sama untuk semua individu di kelompok yang sama.

Contextual effects
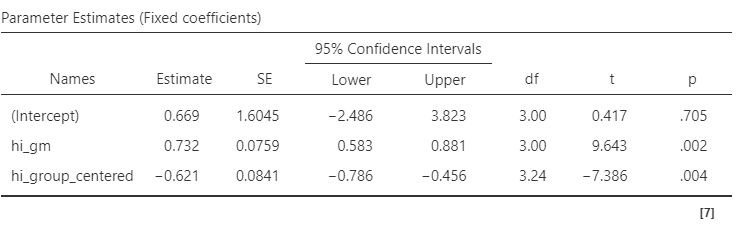
- Between (B = 0.732 95% CI [0.583, 0.881], SE = 0.075, t = 9.64, p = .002), maupun within-group effect (B = -0.621 95% CI [-0.786, -0.456], SE = 0.084, t = -7.386, p = .004) berhubungan dengan tingkat kemandirian siswa.
- Between-group effect: Ada bukti bahwa sekolah dengan rata-rata pendapatan keluarga yang lebih tinggi cenderung memiliki siswa yang lebih mandiri.
- Within-group effect: Di masing-masing sekolah yang sama, siswa dengan tingkat pendapatan keluarga yang lebih tinggi cenderung memiliki tingkat kemandirian yang lebih rendah.
Contextual effects
- Contextual effects (\(\beta_{between_{j}}-\beta_{within_{ij}}\) = 0.732 - (-0.621) = 1.353) menunjukkan bahwa terdapat pengaruh tambahan dari konteks sekolah (e.g., rata-rata tingkat pendapatan keluarga di level sekolah, yang cukup substansial) terhadap kemandirian siswa, yang tidak dapat dijelaskan oleh/diluar dari tingkat pendapatan keluarga siswa itu sendiri (di level individual).
The problem with linear relationship

Ada pertanyaan❓

Note
- Paparan disusun dengan menggunakan dan Quarto dengan template dari UNAIR Theme.
- Kontak saya via amelia.zein@psikologi.unair.ac.id