Confirmatory Factor Analysis (CFA)
Statistik dalam Penelitian Psikologi
2026-06-09
Analisis faktor
Awalnya dikembangkan oleh Charles Spearman (1904) untuk menyelidiki g factor theory of intelligence
Terdiri dari:
- Exploratory factor analysis (EFA)
- Confirmatory factor analysis (CFA)
Analisis faktor digunakan untuk menguji model common variance
Mengasumsikan bahwa dua atau lebih observed variable memiliki shared/common variance (commonality atau common factor) ditunjukkan dengan factor loading

Texas sharpshooter fallacy

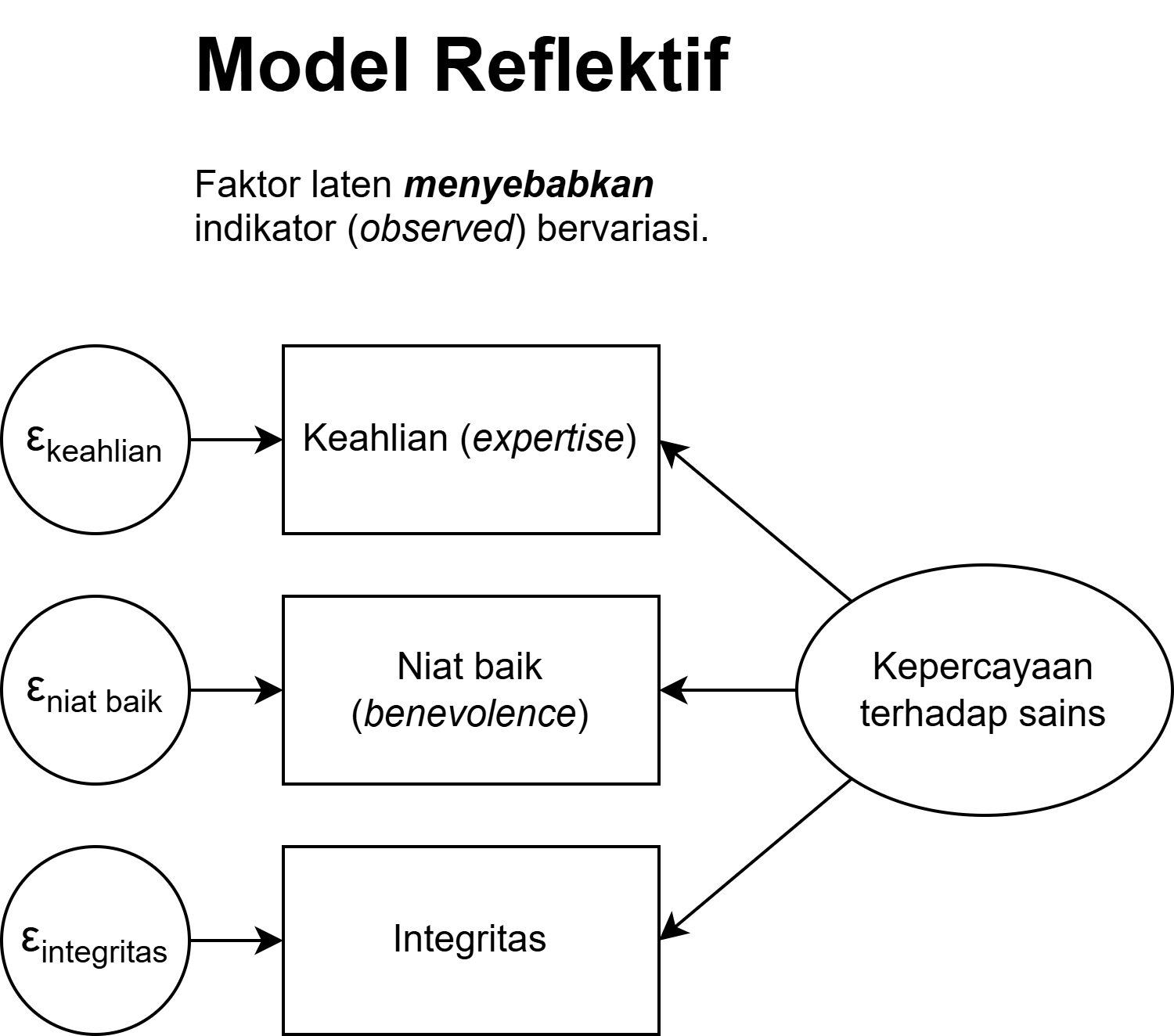
Model Reflektif
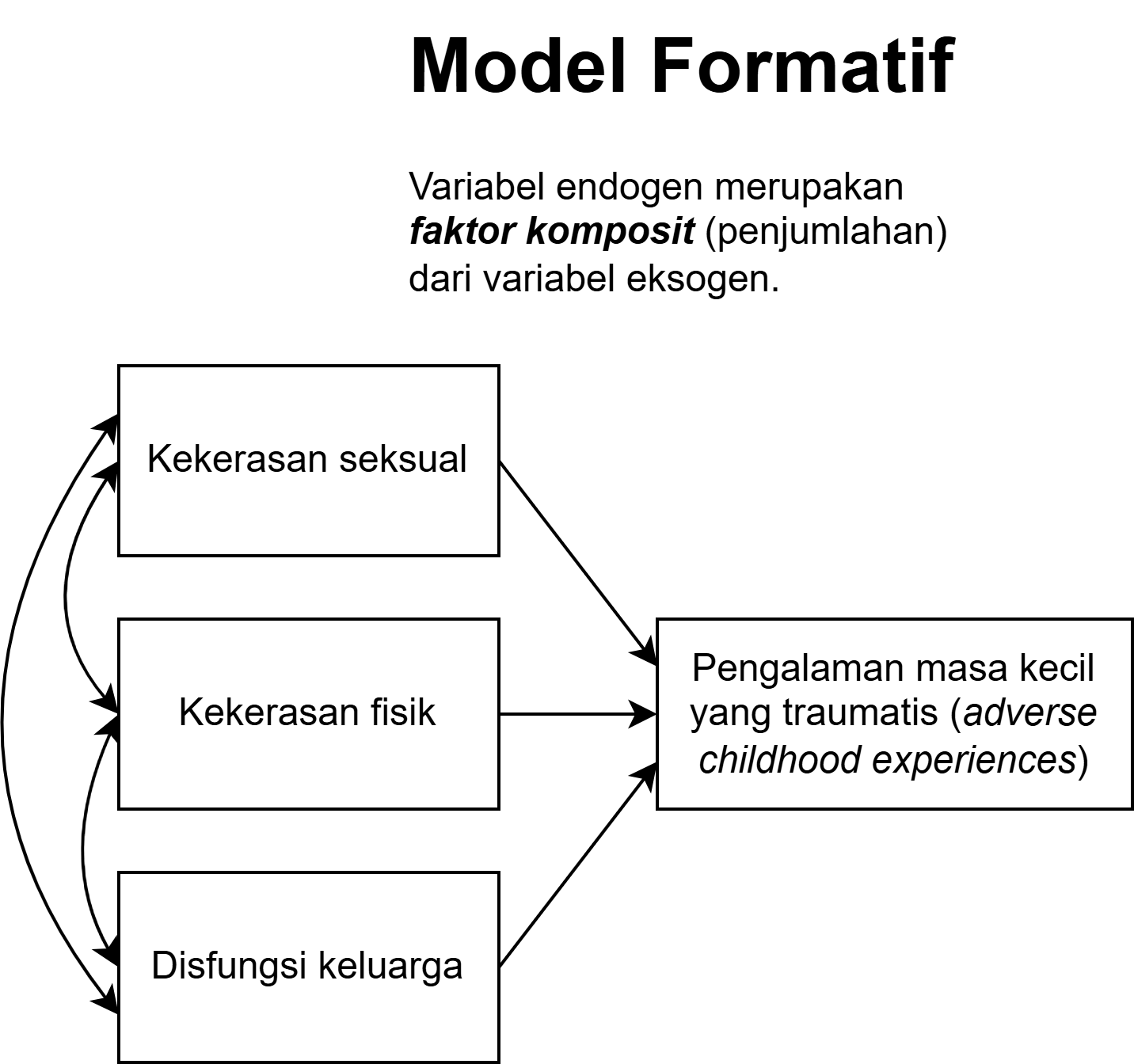
Model Formatif
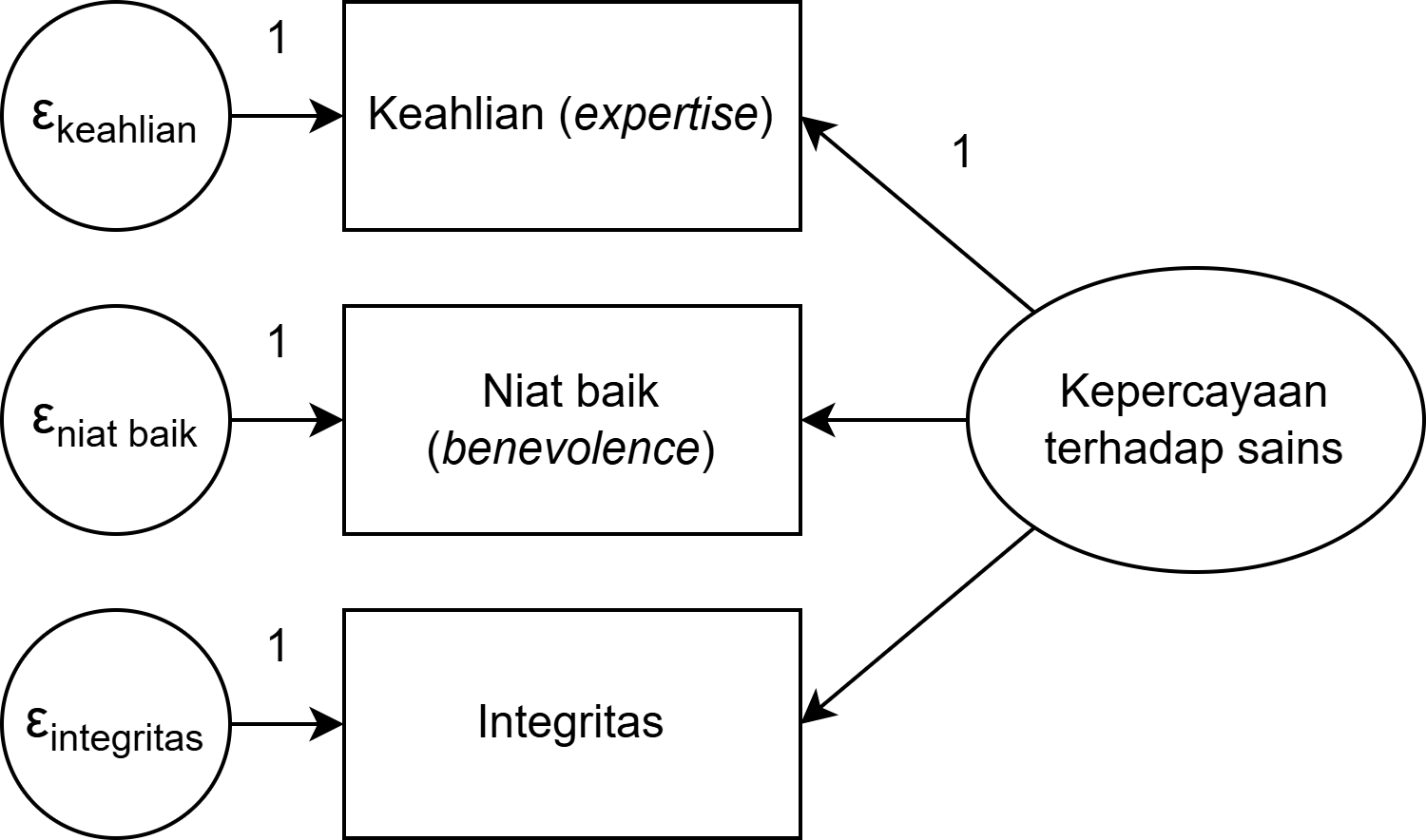
Model congeneric
- Model yang paling longgar asumsunya dan secara default untuk mengestimasi reliabilitas untuk analisis SEM di berbagai perangkat lunak
- Asumsinya, skala, error variance, dan factor loading boleh berbeda (dibebaskan)
- Koefisien reliabilitas skala yang mengasumsikan model pengukuran congeneric ω, McDonald’s ω, ω total (ωt), Revelle’s ω, composite reliability.
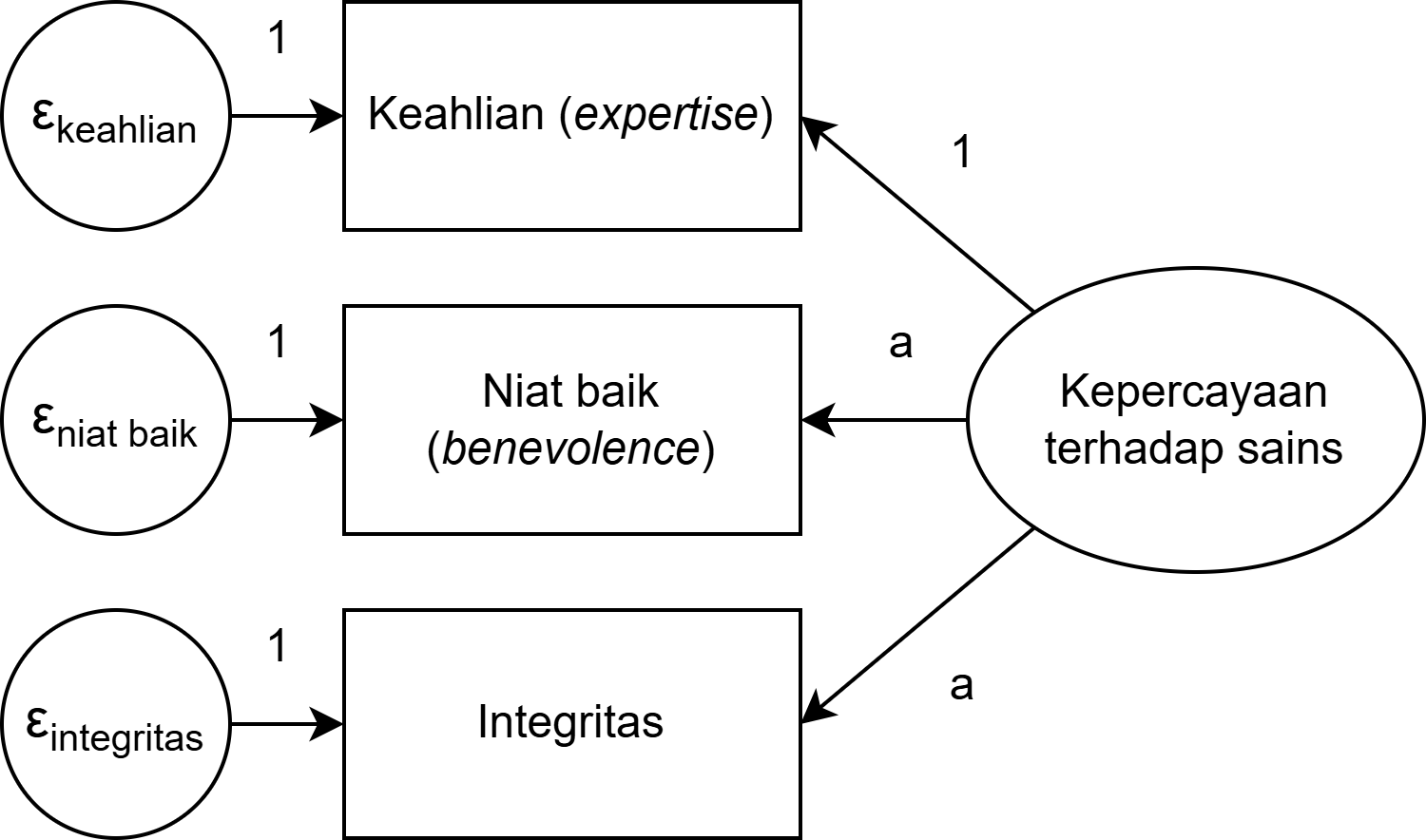
Model tau equivalence
- Model yang sedikit lebih rigid daripada congeneric
- Asumsinya, skala dan error variance boleh berbeda (dibebaskan), namun factor loading harus sama (dibatasi)
- Ketika asumsi tau equivalence dipenuhi, maka Cronbach’s α dapat digunakan
- Koefisien reliabilitas: Formula Rulon, KR-20, Flanagan-Rulon, Guttman’s λ3, λ4, Hoyt method
- Pada kebanyakan kasus, jarang sekali ada konstruk psikologi yang memenuhi asumsi tau equivalence, sehingga sangat disarankan untuk tidak menggunakan koefisien reliabilitas yang mengasumsikan tau equivalence
Model parallel
- Model yang paling rigid
- Asumsinya, skala, error variance, dan factor loading harus sama (dibatasi)
- Koefisien reliabilitas: Spearman-Brown’s Formula, Standardized α.
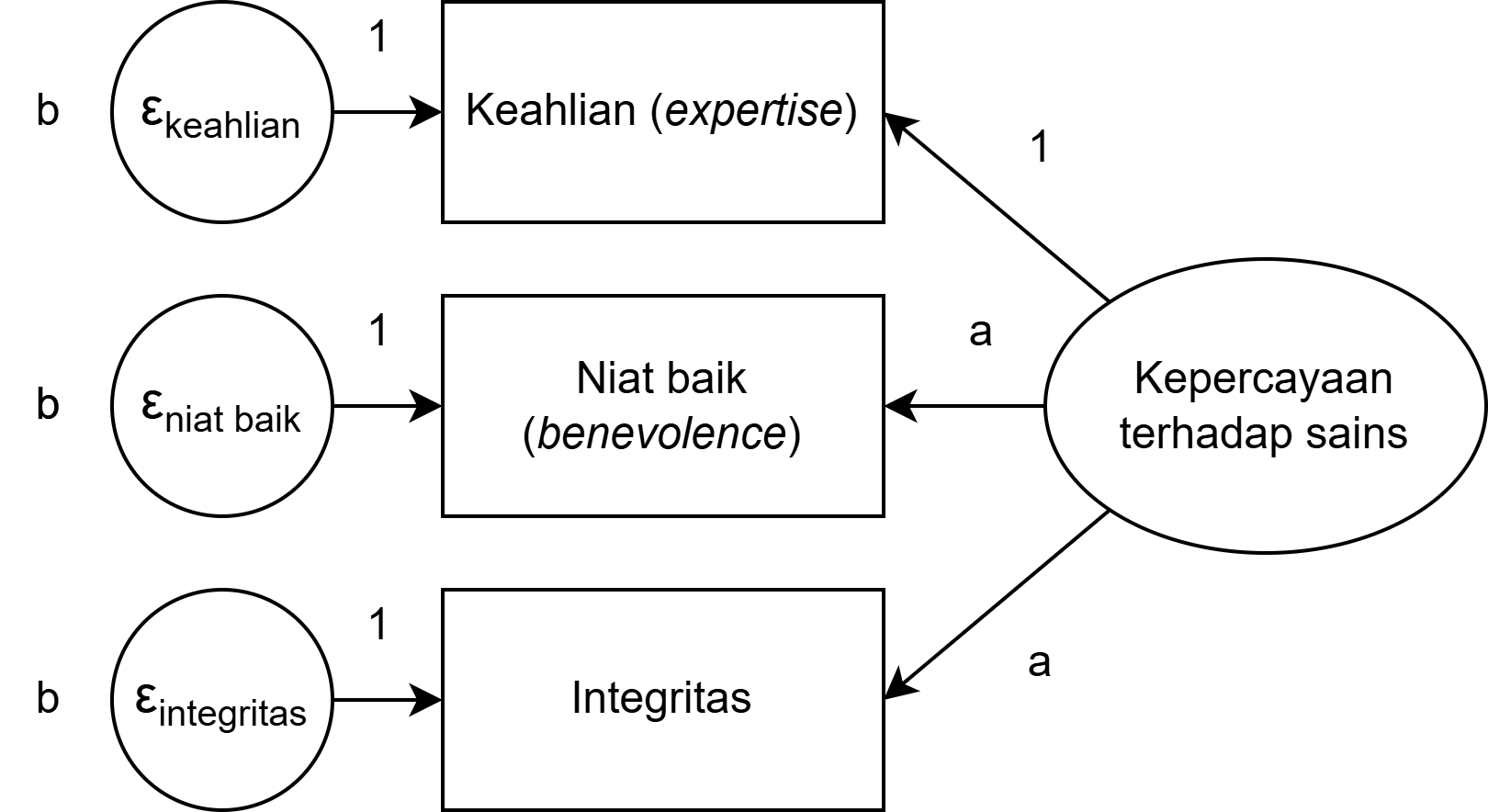
Apa yang terjadi ketika error variance berkorelasi?
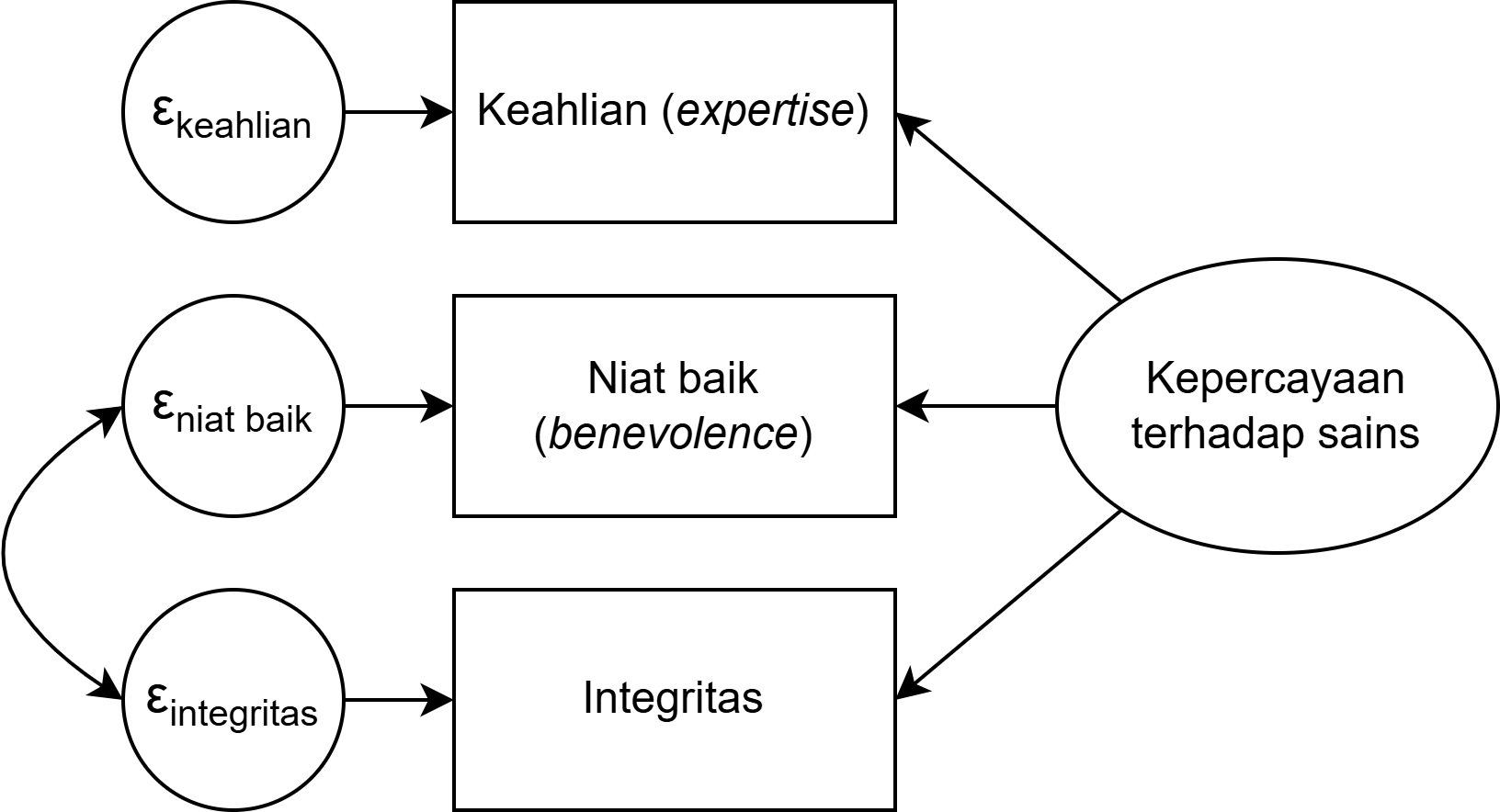
- Kedua variabel indikator tersebut mengukur variabel laten lain di luar model (unique factor)
- Bisa jadi karena ada item unfavorable dalam skala
- Oleh karena itu, dua item berkorelasi bisa berkorelasi apabila penulisan item-nya mirip, hanya saja yang satu positif, sedangkan yang lain penulisannya negatif
- Untuk mencegah hal ini terjadi, sebaiknya hindari menulis item unfavorable dengan kalimat negatif
- Kemungkinan konstruk laten bukan konstruk tunggal (multidimensi)
- Perhatikan justifikasi teori ketika menambah error covariance
AVE vs. Composite Reliability (CR)

Dasar script lavaan
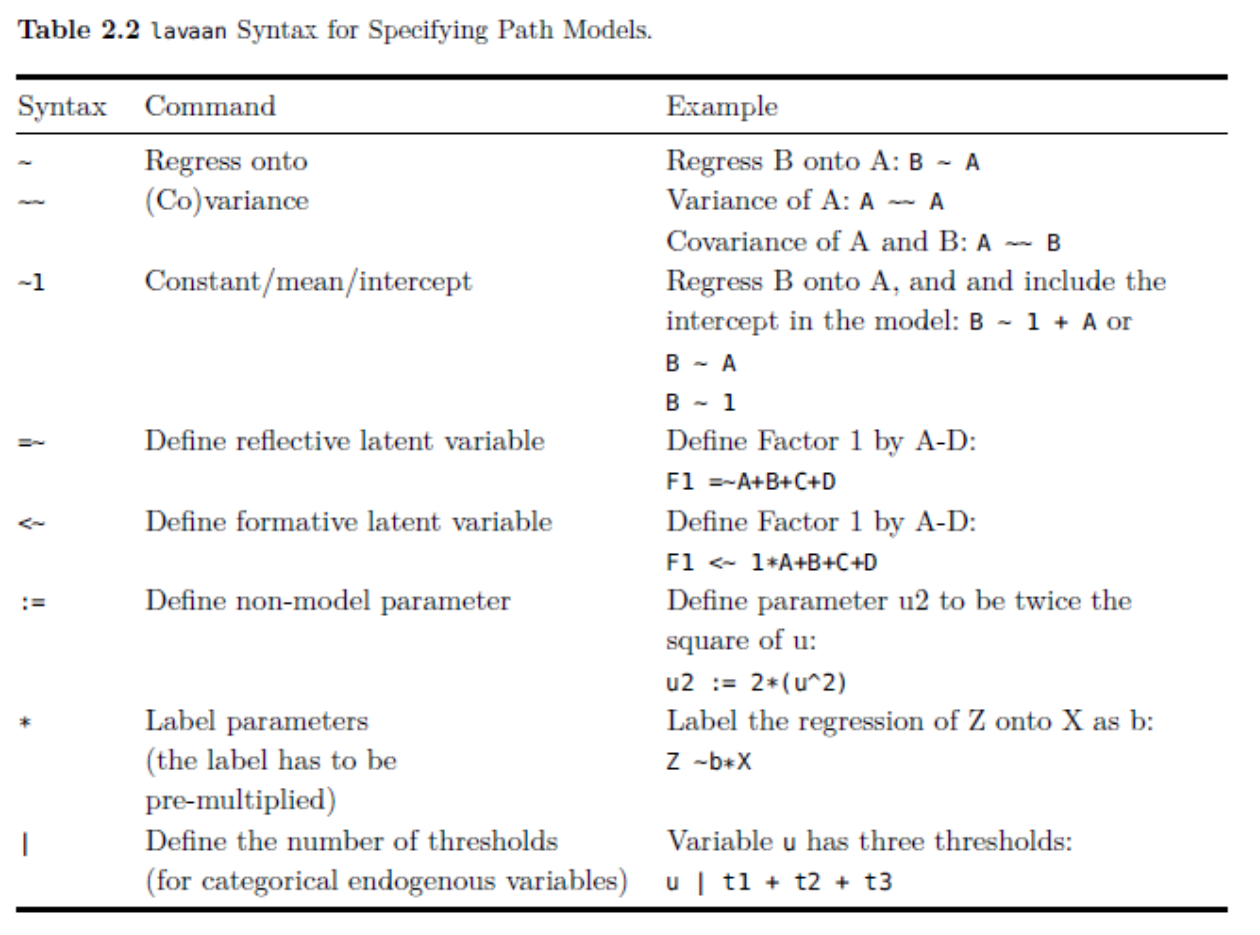
Contoh script lavaan untuk CFA

Ada pertanyaan❓

Note
- Paparan disusun dengan menggunakan dan Quarto dengan template dari UNAIR Theme.
- Kontak saya via amelia.zein@psikologi.unair.ac.id