Regresi Logistik Binomial
Statistik dalam Penelitian Psikologi
2026-04-12
Outline
- Mengapa regresi linear tidak bisa digunakan untuk outcome biner?
- Rantai konsep: probabilitas, odds, log odds, dan odds ratio
- Persamaan model & interpretasi koefisien
- Estimasi model: Maximum Likelihood dan uji fit
- Model dengan banyak prediktor
- Asumsi regresi logistik
- Evaluasi akurasi prediksi
- Pelaporan hasil
Variabel biner dalam penelitian psikologi
Outcome biner ada di berbagai konteks
- Putus studi PJJ: Sepertiga mahasiswa PJJ tidak menyelesaikan studinya sebelum semester kelima (Tinto, 1987; [Park & Choi, 2009(https://www.jstor.org/stable/jeductechsoci.12.4.207)])
- Relapse gangguan kecemasan: 40–60% pasien mengalami kekambuhan dalam jangka panjang setelah remisi (Bruce et al., 2005)
- Turnover karyawan: 15–20% per tahun dianggap normal; di atas angka itu menandakan masalah organisasi (SHRM, 2023)
- Percobaan bunuh diri: Sekitar 2.4% prajurit militer AS melakukan percobaan bunuh diri dalam satu tahun (Kessler et al., 2014)
Note
Outcome ini bukan skor 1–100 (data continous). Mereka adalah keputusan biner: terjadi (1) atau tidak terjadi (0). Kita membutuhkan metode statistik yang dirancang untuk memodelkan probabilitas kejadian seperti ini.
Mengapa bukan regresi linear?
Regresi linear dan prediksi yang mustahil
Misalnya kita ingin memprediksi putus studi mahasiswa PJJ berdasarkan jarak ke kelompok belajar (pokjar):
| Mahasiswa | Jarak ke pokjar | Prediksi P(putus studi) dengan OLS | Valid? |
|---|---|---|---|
| A | 5 km | 0.25 | ✓ |
| B | 50 km | 1.45 | ✗ |
| C | 0 km | −0.10 | ✗ |
- Masalah fundamental: Probabilitas harus berada di rentang 0 sampai 1. Regresi linear tidak menjamin ini — ia memodelkan hubungan linear tanpa batas (∞).
- Yang dibutuhkan: Sebuah fungsi yang secara otomatis membatasi prediksi dalam rentang [0, 1].
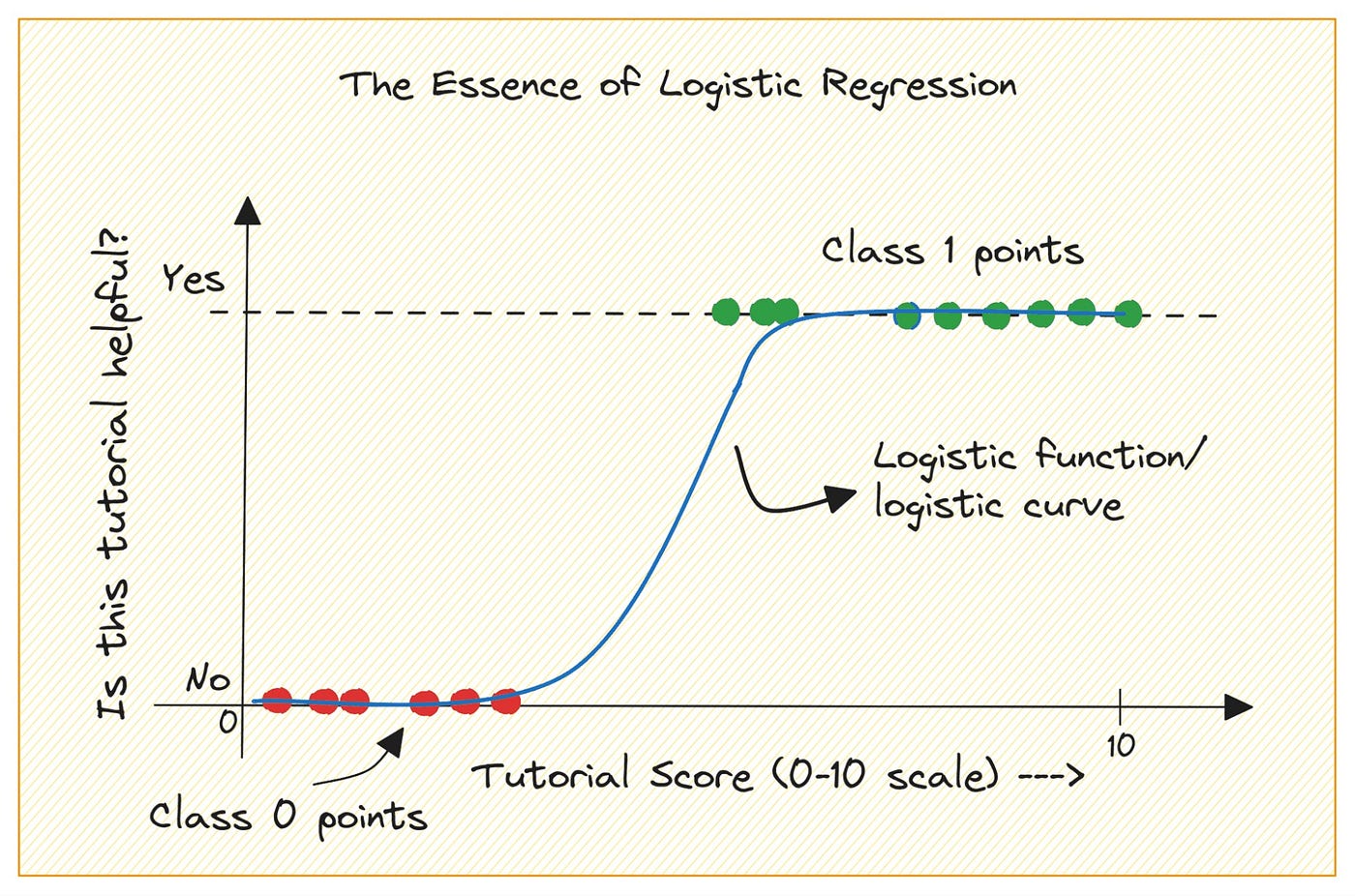
Solusi: fungsi logistik (kurva S)
\[P = \frac{1}{1 + e^{-(\beta_0 + \beta_1 X)}}\]
Tiga sifat penting kurva S (sigmoid):
- Asimptot bawah = 0 — probabilitas tidak pernah negatif
- Asimptot atas = 1 — probabilitas tidak pernah melampaui 1
- Transisi halus di bagian tengah — perubahan probabilitas melambat di ujung-ujungnya
Rentang outcome selalu 0-1 meskipun prediktor nilainya ekstrim
Tidak peduli seberapa ekstrim nilai prediktor (X), probabilitas yang diprediksi tetap berada dalam rentang yang valid. Inilah keunggulan utama regresi logistik dibanding OLS untuk outcome biner.
Rantai konsep: P → Odds → Log Odds → Odds Ratio
Probabilitas 1️⃣
\[P(A) = \frac{\text{jumlah kejadian A}}{\text{total kemungkinan}}\]
Contoh dari dataset PJJ (N = 450):
| Konteks | Probabilitas |
|---|---|
| 135 dari 450 mahasiswa putus studi sebelum semester ke-5 | P(putus studi) = 0.30 |
| 8 dari 200 mahasiswa pernah mencoba bunuh diri | P(percobaan) = 0.04 |
| 60 dari 200 karyawan resign dalam 1 tahun | P(turnover) = 0.30 |
Probabilitas 1️⃣
- Regresi logistik tidak memodelkan probabilitas secara langsung
- Yang dimodelkan adalah transformasinya, yaitu log odds
- Mengapa?
- Karena probabilitas tidak linear, sementara log odds bisa diperlakukan sebagai linear terhadap prediktor
Odds
\[\text{Odds} = \frac{P}{1 - P}\]
Definisi: “Berapa kali suatu kejadian lebih mungkin terjadi dibandingkan tidak terjadi” Contoh: Jika P(putus studi) = 0.30, maka Odds = 0.30 / 0.70 = 0.43
Cara baca: “Untuk setiap 7 mahasiswa yang bertahan, ada 3 yang putus studi” (3:7)
| P(kejadian) | Odds | Cara baca |
|---|---|---|
| 0.10 | 0.11 | 1 banding 9 |
| 0.25 | 0.33 | 1 banding 3 |
| 0.50 | 1.00 | Sama rata |
| 0.75 | 3.00 | 3 banding 1 |
| 0.90 | 9.00 | 9 banding 1 |
Interpretasi odds
- Odds = 1 artinya peluang terjadi sama dengan tidak terjadi.
- Odds > 1 artinya lebih mungkin terjadi; Odds < 1 artinya lebih tidak mungkin.

Log odds (logit) — membuat odds simetris dan linear
Masalah odds: Rentangnya 0 sampai ∞, dan tidak simetris — nilai di bawah 1 terkompresi, nilai di atas 1 tidak terbatas.
Solusi: Log odds (logit)
\[\text{Logit}(P) = \ln\!\left(\frac{P}{1-P}\right)\]
| P | Odds | Logit |
|---|---|---|
| 0.10 | 0.11 | −2.20 |
| 0.25 | 0.33 | −1.10 |
| 0.50 | 1.00 | 0.00 |
| 0.75 | 3.00 | +1.10 |
| 0.90 | 9.00 | +2.20 |
Perhatikan: logit simetris di sekitar 0 dan rentangnya −∞ sampai +∞. Inilah yang dimodelkan secara linear oleh regresi logistik.
Persamaan model regresi logistik
Persamaan dalam logit (yang berjalan di belakang layar):
\[\ln\!\left(\frac{P}{1-P}\right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_k X_k\]
Untuk memprediksi probabilitas, balik transformasinya:
\[P = \frac{1}{1 + e^{-(\beta_0 + \beta_1 X_1 + \cdots + \beta_k X_k)}}\]
Komponen:
- β₀ = intercept (log odds ketika semua prediktor = 0)
- β₁, …, βₖ = koefisien regresi (perubahan logit per satu unit prediktor)
- e^β = Odds Ratio inilah yang diinterpretasikan dalam sebagai effect size dari regresi logistik
Odds Ratio (OR) — ukuran efek utama
\[OR = e^{\beta}\]
OR mengukur seberapa banyak odds berubah ketika prediktor naik 1 unit, dengan prediktor lain dikontrol.
| OR | Interpretasi |
|---|---|
| = 1.00 | Tidak ada efek |
| > 1.00 | Odds outcome naik |
| < 1.00 | Odds outcome turun |
| = 1.50 | Odds naik 50% |
| = 2.00 | Odds naik 100% (dua kali lipat) |
| = 0.50 | Odds turun 50% (setengahnya) |
Selalu laporkan 95% Confidence Interval untuk OR!
Jika CI melewati 1.0, prediktor tidak signifikan secara statistik — misalnya OR = 1.20, 95% CI [0.85, 1.69] → tidak signifikan.
Studi kasus: apa yang memprediksi putus studi PJJ?
Konteks: 450 mahasiswa PJJ; 30% putus studi sebelum semester ke-5
Prediktor: Jarak ke pokjar, keterlibatan akademik, kecemasan akademik awal
| Prediktor | β | OR | 95% CI | p | Interpretasi |
|---|---|---|---|---|---|
| Jarak (per 10 km) | 0.49 | 1.63 | [1.21, 2.19] | <.001 | Jarak +10 km → odds +63% |
| Keterlibatan akademik | −0.65 | 0.52 | [0.38, 0.71] | <.001 | Keterlibatan ↑ → odds −48% |
| Kecemasan akademik | 0.02 | 1.02 | [0.99, 1.05] | .182 | Tidak signifikan |
Interpretasi
Keterlibatan akademik yang tinggi dapat “mencegah” efek jarak yang jauh antara tempat tinggal mahasiswa dengan pokjar. Bisa dijadikan dasar untuk mendesain intervensi program PJJ.
Estimasi & Fit Model
Maximum Likelihood Estimation (MLE)
Regresi linear (OLS):
Cari β yang meminimalkan jumlah kuadrat error (SSE)
Regresi logistik (MLE):
Cari β yang membuat variabel outcome yang kita observasi “paling mungkin terjadi”
Mengapa MLE
Karena MLE, kita tidak mendapatkan F-statistic seperti dalam OLS/ANOVA. Sebagai gantinya, kita mendapatkan χ² sebagai uji signifikansi keseluruhan model.
Jika software menampilkan peringatan Algorithm did not converge — biasanya tanda sampel terlalu kecil atau ada perfect separation (lihat bagian berikutnya).
Deviance & Likelihood Ratio Test — uji omnibus model
Deviance = −2 × log-likelihood (makin kecil, makin baik)
| Deviance | Arti | |
|---|---|---|
| Null deviance | 612.4 | Model tanpa prediktor — “tebakan terbaik tanpa informasi” |
| Residual deviance | 487.2 | Model dengan prediktor kita |
| Penurunan | 125.2 | Bukti bahwa prediktor berguna |
Likelihood Ratio Test:
\[\chi^2 = \text{Null deviance} - \text{Residual deviance}\]
\[\chi^2(3) = 125.2,\ p < .001 \rightarrow \text{Model secara keseluruhan signifikan!}\]
Uji Omnibus
Ini adalah uji omnibus — setara dengan uji F keseluruhan dalam regresi linear. Di jamovi, angka ini muncul di bagian Model Fit sebagai Model χ².
AIC & BIC — memilih model terbaik
Prinsipnya sama dengan regresi OLS yang sudah kita pelajari di Bagian 3: menambah prediktor selalu menurunkan deviance, bahkan jika prediktor itu tidak bermakna (overfitting).
\[\text{AIC} = -2\log L + 2k \qquad \text{BIC} = -2\log L + k\ln(n)\]
Di mana k = jumlah parameter, n = ukuran sampel. Makin kecil, makin baik — hanya bermakna untuk membandingkan model.
| Model | Prediktor | AIC | BIC | |
|---|---|---|---|---|
| Model 1 | Jarak saja | 502.1 | 510.3 | |
| Model 2 | Jarak + Keterlibatan | 489.7 | 502.1 | ← Terbaik |
| Model 3 | Jarak + Keterlibatan + Usia + Gender | 493.2 | 518.9 |
Model 2 menang: fit bagus tanpa terlalu kompleks. BIC lebih ketat dari AIC karena penaltinya lebih besar — pilih BIC jika prioritasnya parsimoni.
Pseudo R² — seberapa banyak variasi yang dijelaskan?
Masalah: Regresi logistik tidak punya R² seperti OLS karena tidak ada “total variance” yang bisa dibagi seperti dalam OLS.
Solusi: Pseudo R² — ada beberapa versi, yang paling sering dilaporkan adalah Nagelkerke R²:
| Nagelkerke R² | Interpretasi |
|---|---|
| < 0.20 | Lemah |
| 0.20–0.40 | Cukup |
| 0.40–0.60 | Baik |
| > 0.60 | Sangat baik |
Interpretasi Pseudo R²
Pseudo R² bukan “proporsi varians yang dijelaskan” seperti R² OLS, jadi jangan diinterpretasikan dengan cara yang sama! Lebih tepat diartikan sebagai “peningkatan fit dibanding null model.” Nilainya cenderung lebih rendah dari R² OLS.
Model dengan Banyak Prediktor
Adjusted OR — efek prediktor setelah mengontrol variabel lain
Masalah confounding: Dalam analisis bivariat, efek yang terlihat bisa dipengaruhi oleh variabel ketiga.
Contoh: Mahasiswa yang tinggal jauh dari pokjar cenderung punya keterlibatan akademik yang lebih rendah (karena kesempatan terlibat lebih terbatas). Efek jarak dan efek keterlibatan saling tumpang tindih.
| Prediktor | Unadjusted OR | Adjusted OR | 95% CI |
|---|---|---|---|
| Jarak (per 10 km) | 1.70 | 1.63 | [1.21, 2.19] |
| Keterlibatan akademik | 0.48 | 0.52 | [0.38, 0.71] |
| Usia (per 10 tahun) | 1.15 | 1.08 | [0.88, 1.32] |
Setelah dikontrol, efek jarak sedikit mengecil — sebagian efeknya bekerja melalui keterlibatan akademik.
Laporkan Adjusted OR
Dalam artikel ilmiah, selalu laporkan adjusted OR dari model dengan prediktor berganda, bukan unadjusted OR dari analisis bivariat.
Interaksi — efek prediktor yang berbeda antar subgrup
Pertanyaan: Apakah efek jarak pada putus studi berbeda tergantung tingkat keterlibatan akademik?
\[\text{logit}(P) = \beta_0 + \beta_1(\text{Jarak}) + \beta_2(\text{Keterlibatan}) + \beta_3(\text{Jarak} \times \text{Keterlibatan})\]
Hasil: β₃ = −0.08, p = .03 → Interaksi signifikan!
| Subgrup | Efek jarak pada odds putus studi | Interpretasi |
|---|---|---|
| Keterlibatan rendah | OR = 1.12 per km | Jarak sangat berpengaruh |
| Keterlibatan tinggi | OR = 1.02 per km | Jarak hampir tidak berpengaruh |
Tip
Keterlibatan akademik yang tinggi bisa men-buffer dampak jarak yang jauh, sehingga bisa dijadikan dasar untuk merancang intervensi yang tepat sasaran.
Strategi membangun model — mulai dari teori
✅ Theory-driven (direkomendasikan)
- Pilih prediktor berdasarkan teori dan literatur sebelum melihat data
- Uji hipotesis yang sudah pre-specified
- Laporkan semua model yang diuji — bukan hanya yang paling bagus hasilnya secara statistik
⚠️ Stepwise selection (kontroversial)
- Forward: tambahkan prediktor satu per satu berdasarkan p-value
- Backward: mulai dari semua prediktor, hapus yang tidak signifikan
- Masalah: Overfitting, inflasi Type I error, hasil tidak replicable
Kapan analisis eksplorasi dibenarkan?
Analisis eksplorasi boleh dilakukan untuk generate hipotesis, tapi harus dipisahkan dari analisis konfirmatori. Mencampur keduanya dalam satu sampel adalah salah satu bentuk questionable research practice.
Asumsi Regresi Logistik
Kabar baik: lebih longgar dari OLS!
Yang HARUS dipenuhi:
- Outcome biner (variabel dependen dikotomus: 0/1)
- Observasi independen — satu partisipan tidak mempengaruhi yang lain
- Linearitas dalam log odds — prediktor kontinu harus punya hubungan linear dengan logit(P)
- Tidak ada multikolinearitas ekstrem
Yang TIDAK perlu:
- ✗ Normalitas residual
- ✗ Homoskedastisitas
- ✗ Outcome kontinu
- ✗ Hubungan linear antara prediktor dan P (hanya harus linear dalam logit)
Tetap harus dicek
Meskipun lebih longgar, asumsi yang ada tetap harus dicek dan dilaporkan. Terutama multikolinearitas (dengan VIF) dan kemungkinan perfect separation.
Multikolinearitas — sudah familiar dari Bagian 3
Cara memeriksa dan interpretasinya sama persis seperti dalam regresi OLS — gunakan VIF:
| VIF | Interpretasi |
|---|---|
| < 5 | Tidak ada masalah |
| 5–10 | Moderate — perlu hati-hati |
| > 10 | Masalah serius |
Contoh masalah: “Durasi studi (semester)” dan “biaya pendidikan kumulatif” — keduanya naik bersama, korelasi r = 0.95 → VIF ≈ 18 → tidak bisa diestimasi secara stabil.
Tip
Jamovi menampilkan VIF secara otomatis di output regresi logistik — centang Collinearity Statistics di opsi Model Coefficients.
Perfect separation — ketika prediktor too goood to be true
Masalah: Satu prediktor memisahkan outcome secara sempurna — semua Y = 1 ada di satu sisi, semua Y = 0 di sisi lain.
Contoh: Semua mahasiswa dengan jarak > 45 km putus studi (100%). Semua mahasiswa dengan jarak ≤ 45 km lanjut studi (100%).
Akibat: Koefisien meluncur ke ±∞, standard error sangat besar, model tidak converge.
Tanda-tanda di output
- Koefisien sangat besar (β > 10 atau < −10)
- Standard error sangat besar
- Pesan “Algorithm did not converge”
Jika ini terjadi, cek distribusi prediktor dan outcome — sering kali tanda bahwa ada kategori yang terlalu kecil.
Evaluasi Akurasi Prediksi
Confusion matrix — dasar evaluasi akurasi
Setelah model difit, gunakan threshold default P ≥ 0.50 → prediksi outcome terjadi; P < 0.50 → prediksi tidak terjadi.
| Prediksi: Tidak Terjadi | Prediksi: Terjadi | |
|---|---|---|
| Aktual: Tidak Terjadi | 240 (TN) | 30 (FP) |
| Aktual: Terjadi | 50 (FN) | 130 (TP) |
- TP (True Positive): Prediksi terjadi → aktual terjadi ✓
- TN (True Negative): Prediksi tidak terjadi → aktual tidak terjadi ✓
- FP (False Positive): Prediksi terjadi → aktual tidak terjadi ✗ (false alarm)
- FN (False Negative): Prediksi tidak terjadi → aktual terjadi ✗ (miss — sering yang paling berbahaya)
Sensitivity, specificity, dan akurasi
Dari confusion matrix tadi (TP=130, TN=240, FP=30, FN=50, N=450):
| Metrik | Formula | Nilai | Pertanyaan yang dijawab |
|---|---|---|---|
| Akurasi | (TP+TN)/N | 82.2% | Berapa % prediksi yang benar? |
| Sensitivity | TP/(TP+FN) | 72.2% | Dari yang benar-benar terjadi, berapa % terdeteksi? |
| Specificity | TN/(TN+FP) | 88.9% | Dari yang tidak terjadi, berapa % diprediksi benar? |
Trade-off sensitivity vs specificity
- Screening risiko bunuh diri → prioritaskan sensitivity tinggi — lebih baik over-identify daripada ada yang terlewat
- Diagnosis klinis formal → prioritaskan specificity tinggi — false positive berdampak stigma dan biaya
Default threshold = 0.50 — bisa disesuaikan sesuai konteks dan pertimbangan etis.
AUC — ringkasan performa model dalam satu angka
AUC (Area Under the ROC Curve) = probabilitas bahwa model memberikan predicted probability yang lebih tinggi kepada kasus positif dibanding kasus negatif yang diambil secara acak.
| AUC | Interpretasi |
|---|---|
| 0.50 | Tidak lebih baik dari tebakan |
| 0.60–0.70 | Lemah |
| 0.70–0.80 | Cukup |
| 0.80–0.90 | Baik |
| > 0.90 | Sangat baik — atau overfitting? Cek dulu! |
Note
ROC curve dan AUC tersedia di jamovi. Pembahasan mendalam tentang analisis ROC — termasuk PPV/NPV, Youden’s Index, dan penentuan cut-off optimal — ada di Bagian 4.
Pelaporan Hasil
Checklist pelaporan regresi logistik
☐ Deskripsi variabel — outcome biner (0/1), distribusi prediktor
☐ Uji signifikansi model — Model χ², df, p (dari Likelihood Ratio Test)
☐ Pseudo R² — Nagelkerke R²
☐ Koefisien per prediktor — β, SE, Wald χ², p, OR, 95% CI
☐ Multikolinearitas — VIF
☐ Akurasi klasifikasi — akurasi keseluruhan, sensitivity, specificity
☐ AUC (opsional tapi dianjurkan)
☐ AIC/BIC jika membandingkan model
Contoh paragraf hasil
“Regresi logistik binomial dilakukan untuk memprediksi putus studi mahasiswa PJJ menggunakan tiga prediktor: jarak ke pokjar, kecemasan akademik awal, dan keterlibatan akademik. Model secara keseluruhan signifikan, χ²(3, N = 450) = 125.2, p < .001, Nagelkerke R² = .32. Model berhasil mengklasifikasikan 82.2% kasus dengan benar (sensitivity = 72.2%, specificity = 88.9%, AUC = .84).
Jarak ke pokjar secara signifikan memprediksi putus studi (OR = 1.05, 95% CI [1.02, 1.08], p < .001): setiap tambahan 10 km jarak dari pokjar, odds putus studi mahasiswa meningkat sebesar 63%. Keterlibatan akademik juga berperan signifikan (OR = 0.52, 95% CI [0.38, 0.71], p < .001) — mahasiswa dengan keterlibatan lebih tinggi memiliki odds putus studi yang lebih rendah. Kecemasan akademik awal tidak memprediksi putus studi secara signifikan (OR = 1.02, 95% CI [0.99, 1.05], p = .182).”
Menerjemahkan OR ke bahasa yang dipahami semua orang
Jangan serahkan interpretasi ke pembaca — terjemahkan OR ke kalimat yang konkrit.
Contoh: OR = 1.05 untuk jarak ke pokjar (per 1 km)
Opsi 1 — Persentase perubahan odds: “Setiap tambahan 1 km jarak dari pokjar, odds putus studi naik 5%.”
Opsi 2 — Interval konkrit: “Mahasiswa yang tinggal 10 km lebih jauh punya odds putus studi 1.63 kali lebih tinggi.” (karena 1.05^10 = 1.63)
Opsi 3 — Perbandingan probabilitas: “Mahasiswa yang tinggal 5 km dari pokjar memiliki peluang ~20% putus studi; mahasiswa yang tinggal 15 km memiliki peluang ~30%.”
Warning
OR ≠ Risk Ratio (RR). Jangan tulis “X kali lebih mungkin” untuk OR — itu bahasa RR. OR harus dikatakan: “X kali lebih tinggi odds-nya” (Zhang & Yu, 1998, JAMA). Perbedaan ini penting terutama jika prevalensi outcome > 10%.
Enam kesalahan umum
Mengaburkan OR dengan Risk Ratio — “X kali lebih mungkin” bukan cara yang benar untuk menginterpretasikan OR. Kata yang tepat: “X kali lebih tinggi odds-nya”.
Mengklaim kausalitas — Regresi logistik adalah korelasional. Kausalitas membutuhkan desain eksperimental atau quasi-eksperimental.
Mengabaikan multikolinearitas — “Usia” dan “tahun lahir” keduanya dimasukkan sebagai prediktor? Sudah pasti multikolinear.
Tidak memeriksa asumsi — Terutama linearitas dalam logit dan kemungkinan perfect separation.
Hanya melaporkan prediktor yang signifikan — Laporkan semua prediktor yang dimasukkan ke model — bukan cherry-pick yang p < .05.
EPV terlalu rendah — Events per variable (EPV): minimal 10 kejadian per prediktor. Dengan hanya 50 kejadian (events), jangan masukkan lebih dari 5 prediktor — estimasi akan tidak stabil.
Demonstrasi di jamovi
Konteks: apa yang memprediksi pemberian dukungan sosial?
- Dataset: Dataset Contoh Regresi Logistik (
dataset-social-support.omv)- Dapat diunduh dari navbar di laman mata kuliah
- Pertanyaan penelitian berkaitan dengan faktor-faktor yang memprediksi outcome biner dalam konteks psikologi klinis/sosial
Langkah-langkah di jamovi
Menjalankan regresi logistik:
- Analyses → Regression → Logistic Regression → 2 Outcomes (Binomial)
- Masukkan variabel outcome ke Dependent Variable
- Masukkan prediktor ke Covariates (kontinu) atau Factors (kategorikal)
- Jamovi akan melakukan dummy coding secara otomatis untuk variabel kategorikal
Output yang harus dicek:
☑ Model Fit — Model χ², Nagelkerke R²
☑ Model Coefficients — β, OR, 95% CI, p
☑ Collinearity Statistics — VIF
☑ Prediction Table — akurasi, sensitivity, specificity
☑ ROC Curve — AUC
Urutan membaca output
Omnibus (Model χ²) → Pseudo R² → Koefisien per prediktor (OR + CI) → VIF → Akurasi klasifikasi → AUC
Ada pertanyaan❓

Note
- Paparan disusun dengan menggunakan dan Quarto dengan template dari UNAIR Theme.
- Kontak saya via amelia.zein@psikologi.unair.ac.id