Pengantar Latent Variable Modeling
Statistik dalam Penelitian Psikologi
2026-04-12
Apakah fisika lebih mudah dari psikologi?

- Fisika mengukur massa, kecepatan, suhu — semuanya bisa dikuantifikasi langsung dengan alat fisik.
- Psikologi mengukur kecemasan, kepribadian, motivasi — konstruk yang tidak bisa ditimbang atau diukur dengan penggaris.
- Pertanyaannya: bagaimana kita tahu bahwa alat ukur kita benar-benar mengukur konstruk yang dimaksud?
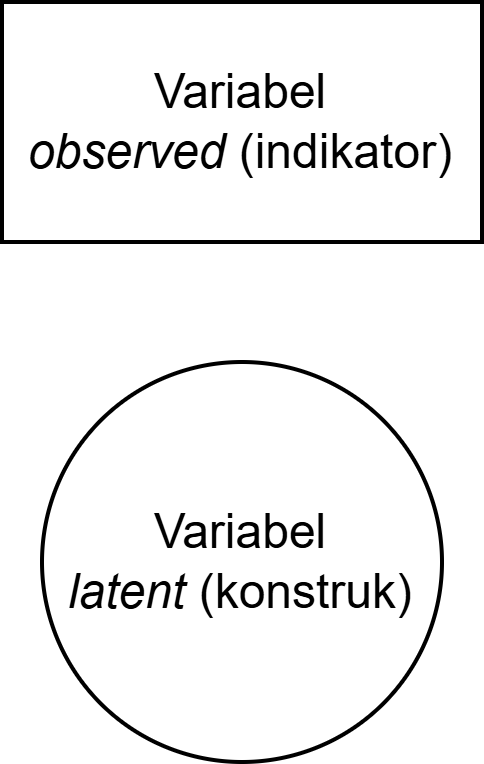
Variabel observed vs variabel laten
- Variabel observed (variabel manifes)
- Variabel yang dapat diukur atau diamati secara langsung.
- Dalam skala psikologi: setiap item pernyataan adalah variabel observed.
- Dalam studi eksperimen: skor tes, waktu reaksi, frekuensi perilaku.
- Variabel laten
- Konstruk yang tidak dapat diukur secara langsung — hanya bisa diinferensi.
- Membutuhkan seperangkat variabel observed untuk mengoperasionalisasikannya.
- Variabel observed berperan sebagai indikator dari variabel laten.
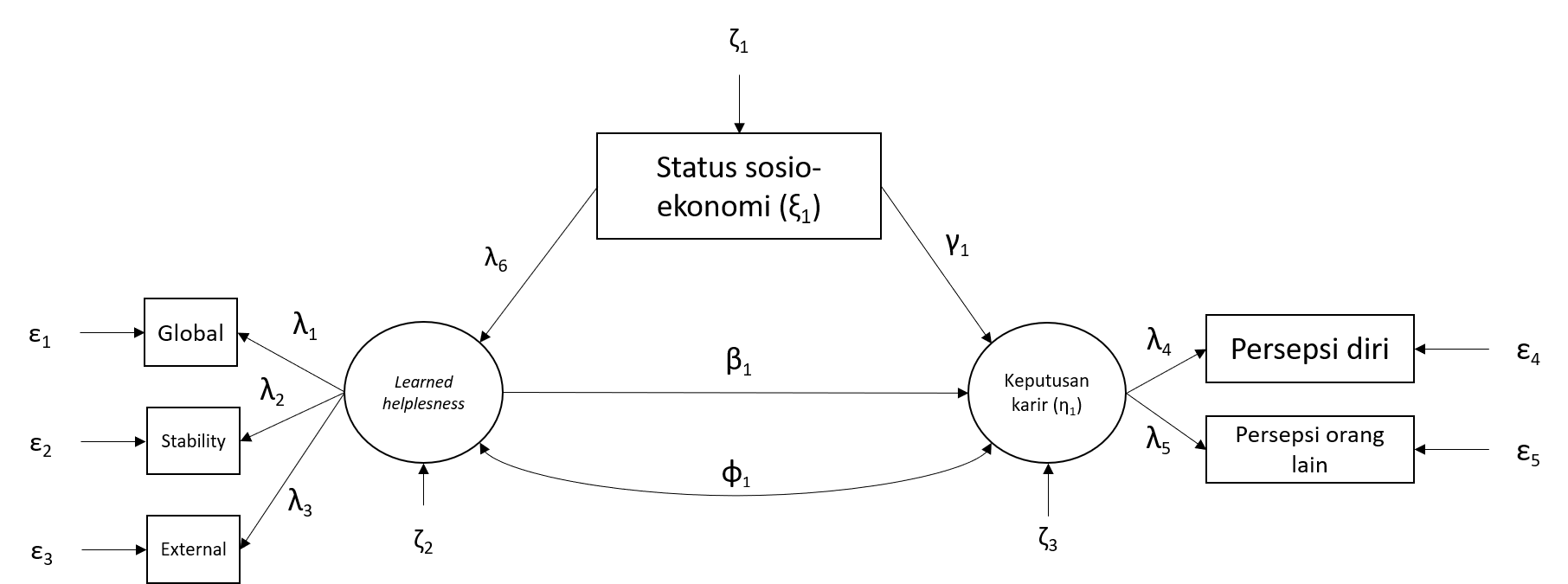
Komponen model SEM
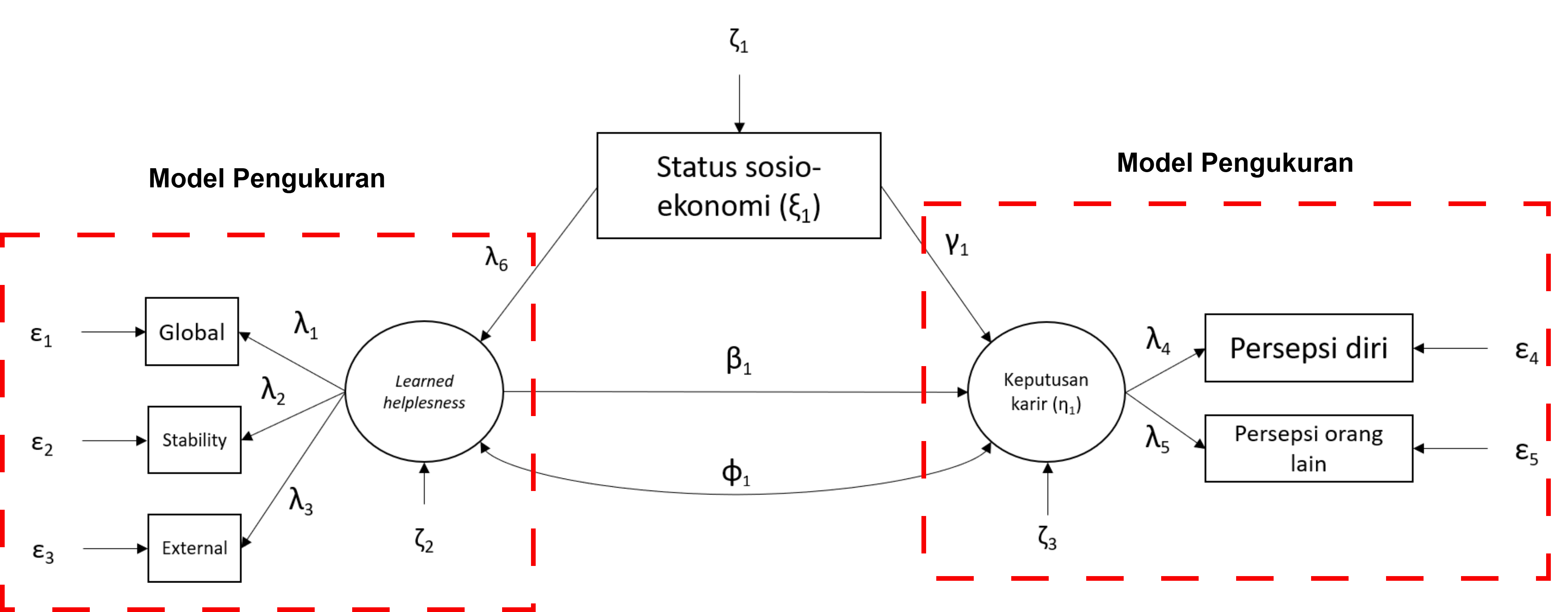
Model pengukuran (measurement model)
Reflektif vs. Formatif: visualisasi
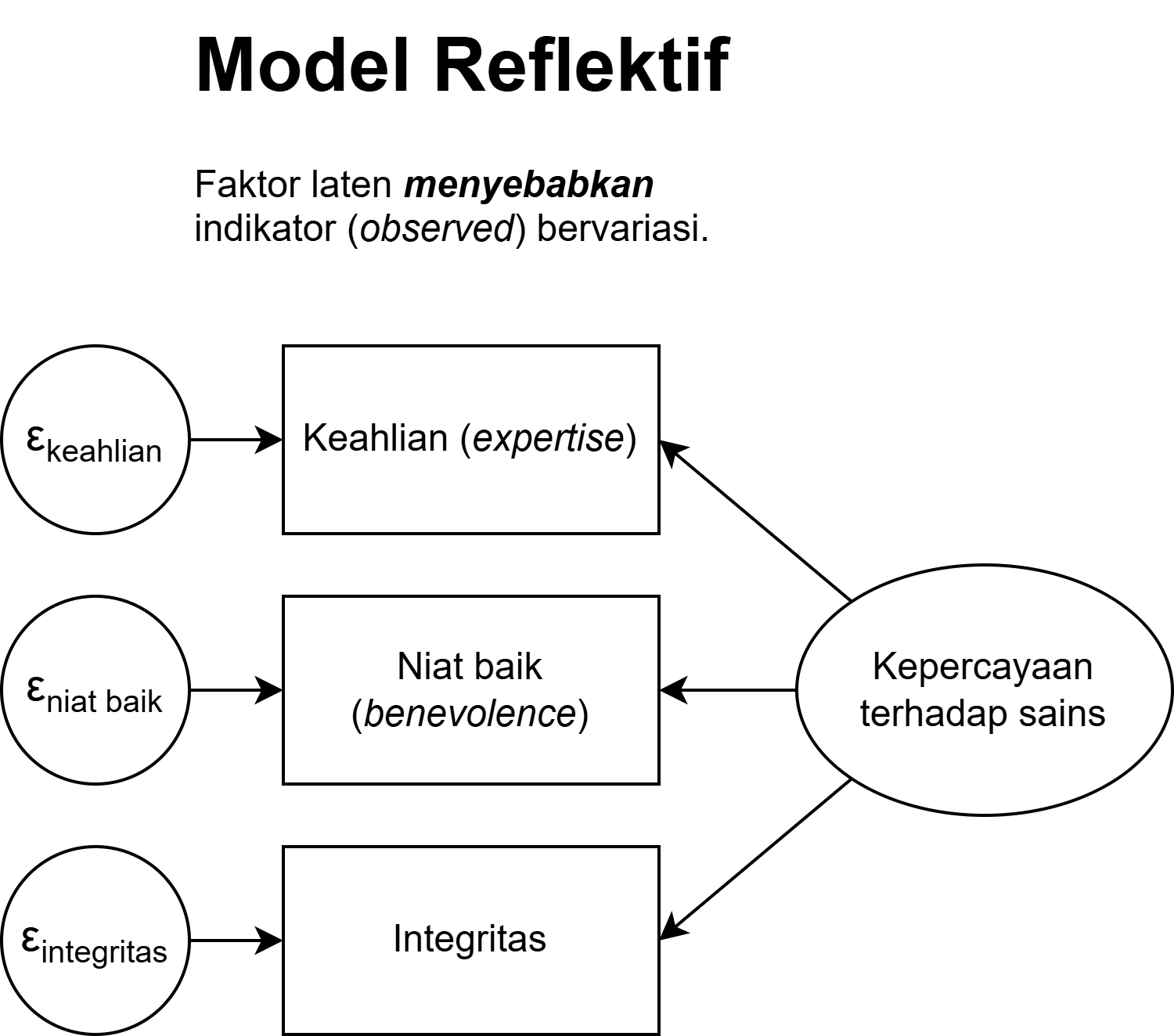
Reflektif: panah dari laten ke indikator
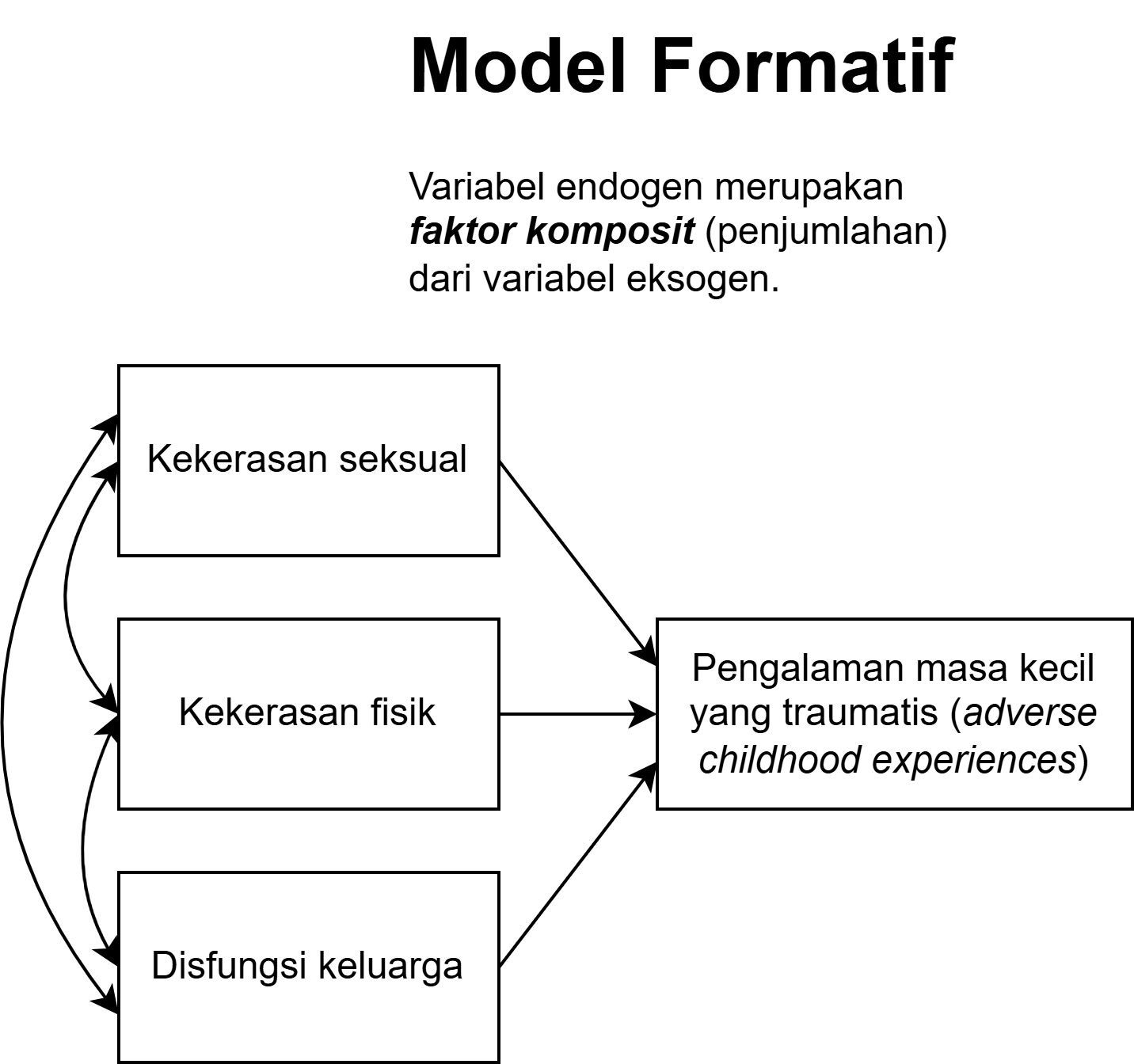
Formatif: panah dari indikator ke laten
Mengapa ini penting?
Mayoritas konstruk psikologi menggunakan model reflektif, misalnya: skala kepribadian, kecemasan, depresi, dll. Menggunakan model formatif untuk konstruk reflektif (atau sebaliknya) adalah kesalahan konseptual yang serius.
Ada pertanyaan❓

Note
- Paparan disusun dengan menggunakan dan Quarto dengan template dari UNAIR Theme.
- Kontak saya via amelia.zein@psikologi.unair.ac.id